Data Cleaning for Data Sharing
Using R
About the Speaker
- Independent Research Data Management Consultant
- Previously data manager for the Missouri Prevention Science Institute
- Co-organizer for R-Ladies St. Louis
- Co-organizer for the POWER Data Management in Education Research Hub
- Author Data Management in Large-Scale Education Research

Introductions
- Your name
- Your affiliation
- Your role

3 Phases of Data
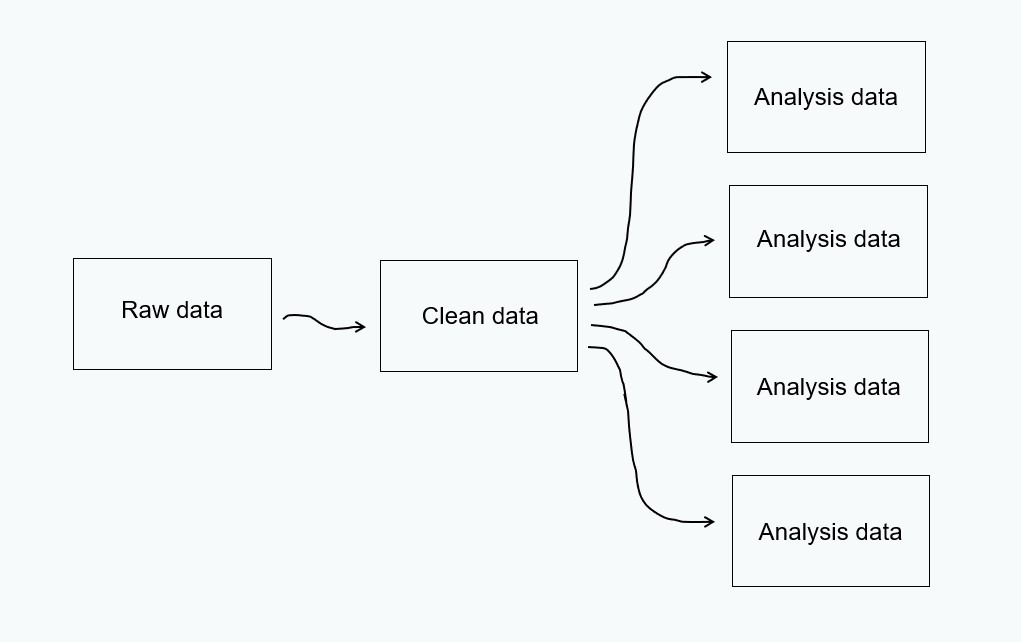
A Sampling of Open Datasets
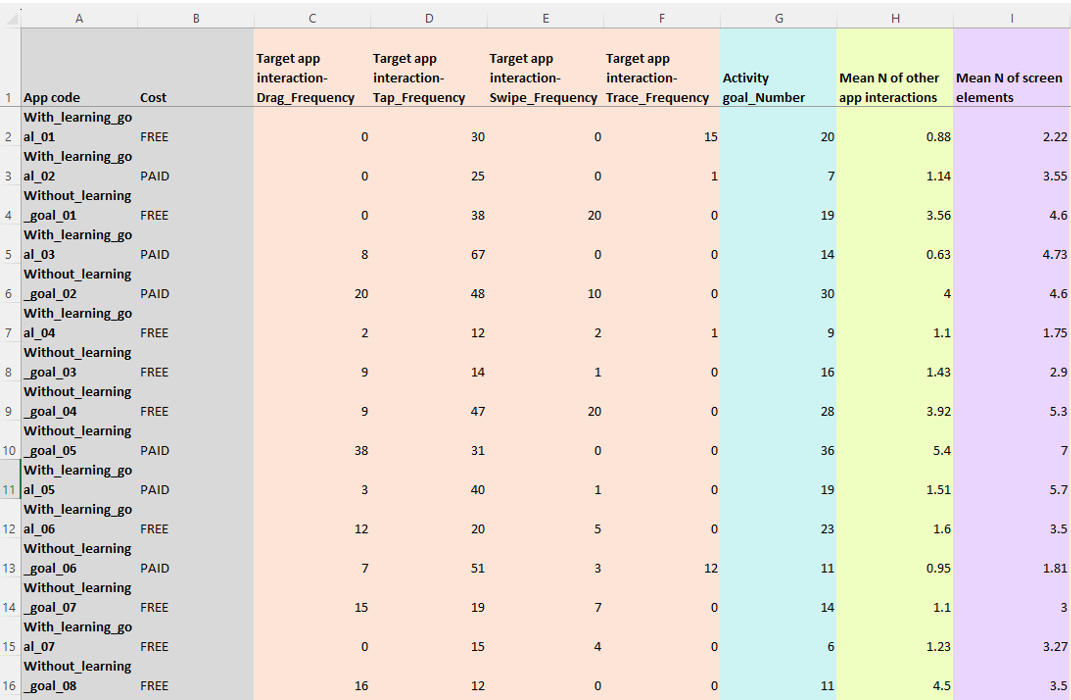
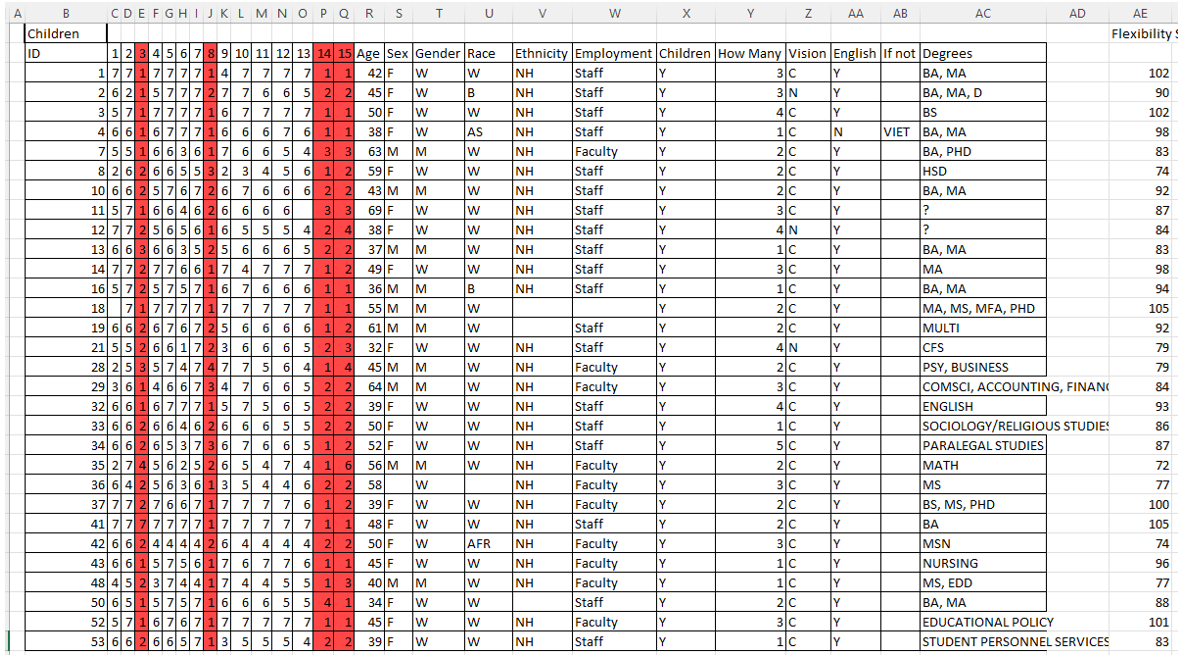
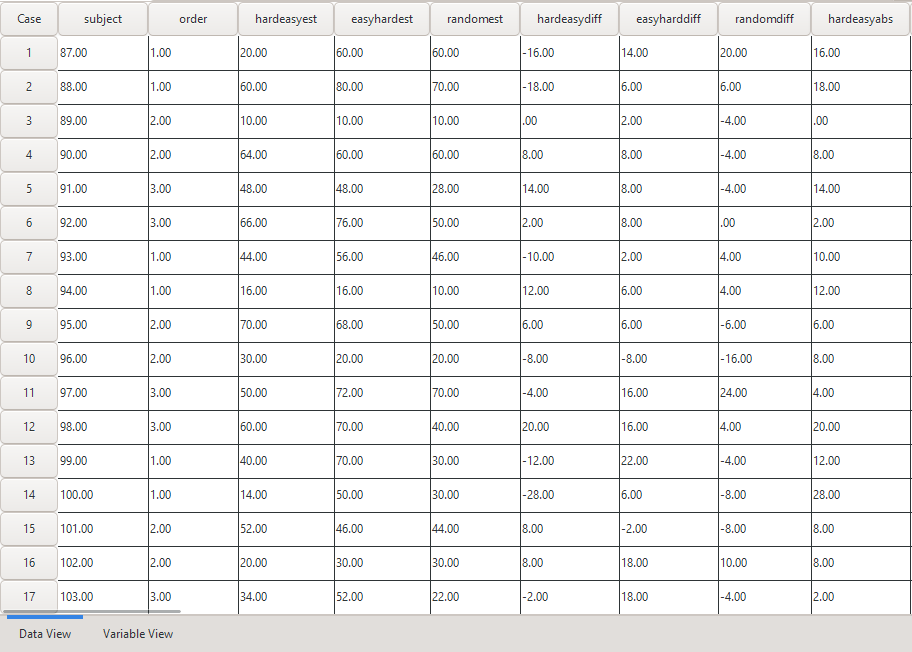
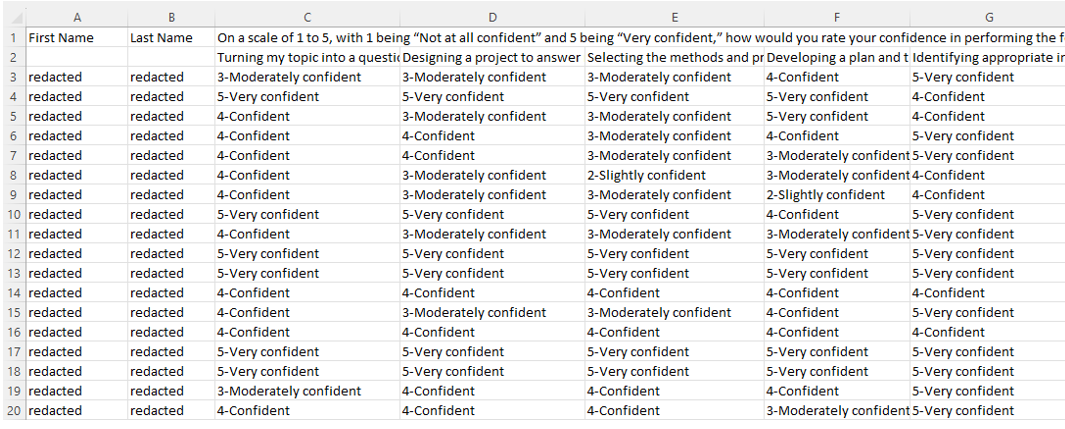

The Data are Ready

7 Data Quality Indicators
Analyzable
Interpretable
Complete
Valid
Accurate
Consistent
De-identified

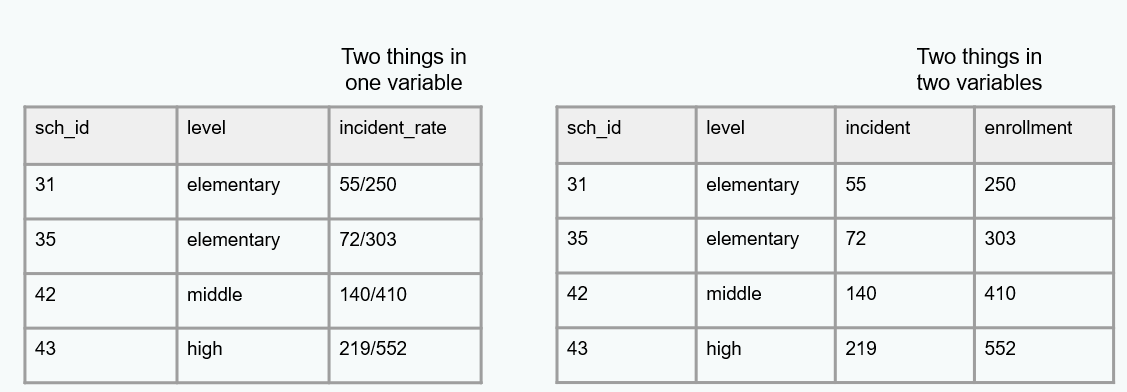
Analyzable
- Data should make a rectangle of rows and columns
- The first row, and only the first row, is your variable names
- The remaining data should be made up of values in cells
- At least one column uniquely defines the rows in the data (e.g., unique identifier)
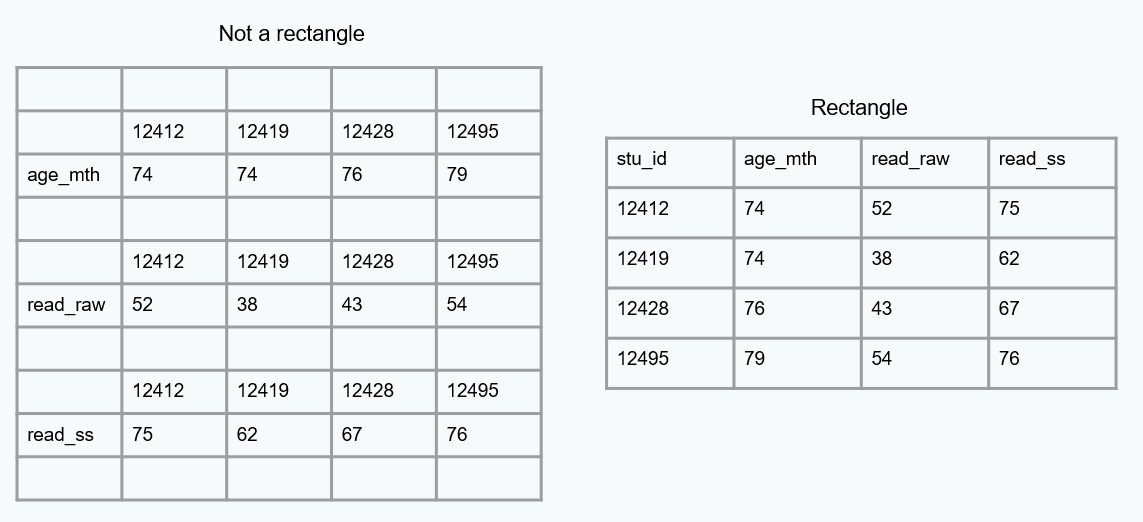
Analyzable
- Column values are analyzable
- Information is explicit
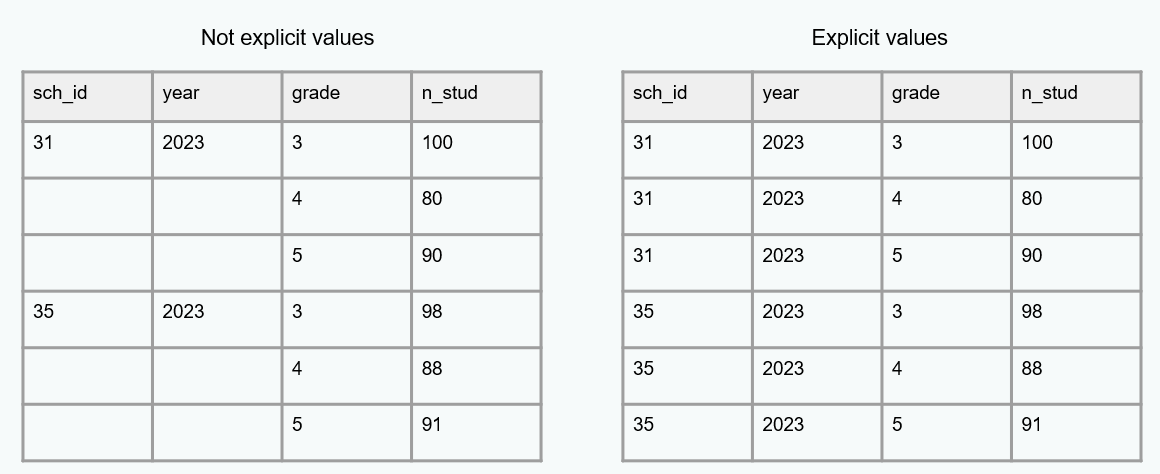
Analyzable
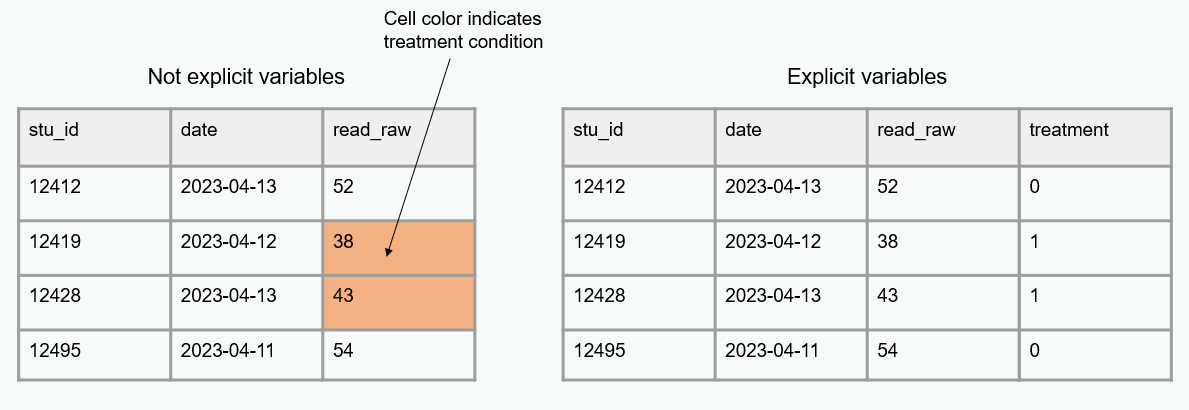
Analyzable
- Only one piece of information is collected per variable
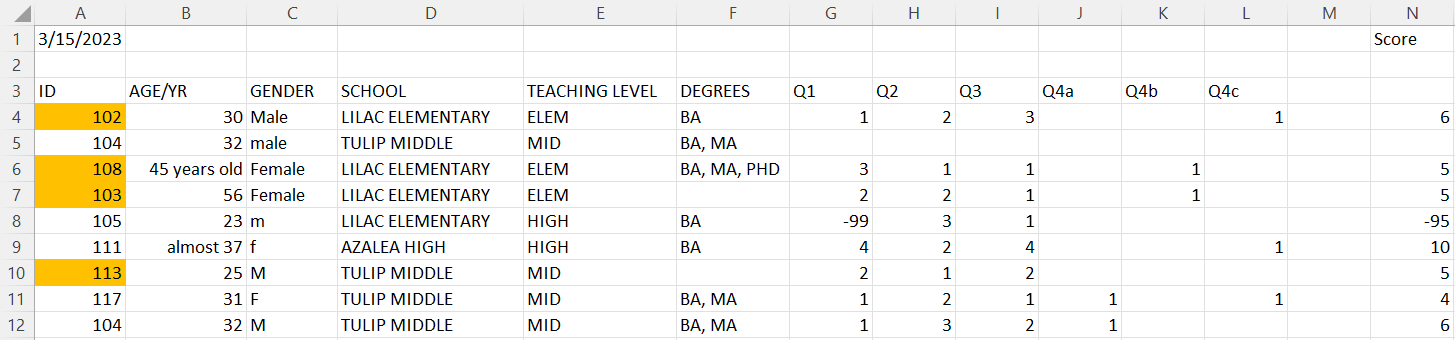
Exercise
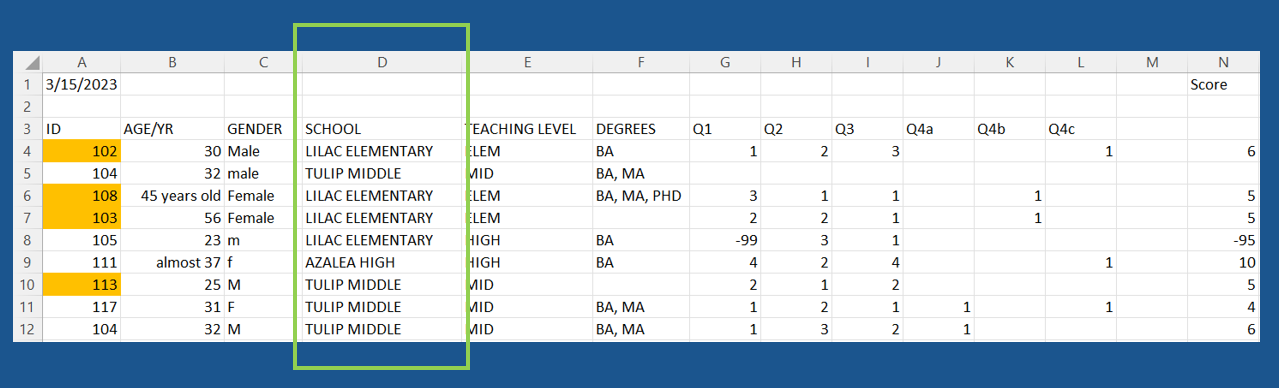
What data quality issues do you detect for the analyzable indicator?
01:00
Solution
- Data does not make a rectangle
- Color coding used to convey information
- More than one piece of information in a variable
- Blank values implied to be 0 for
Q4variables
Interpretable
- Variable names should be machine-readable
- Unique
- No spaces or special characters except
_- This includes no
.or-
- This includes no
- Not begin with a number
- Character limit of 32
- Variable names should be human-readable
- Meaningful (
genderinstead ofQ1) - Consistently formatted (capitalization and delimiters)
- Consistent order of information
wave_responder_scale#(w1_t_mast1)
- Meaningful (
Interpretable
- When publicly sharing data, it is recommended to share data in at least one non-proprietary format (e.g., CSV)
- But if you would also like to share a copy in a commonly used format such as SPSS, SAS, or Stata, consider adding embedded metadata (i.e., variable label and value labels)
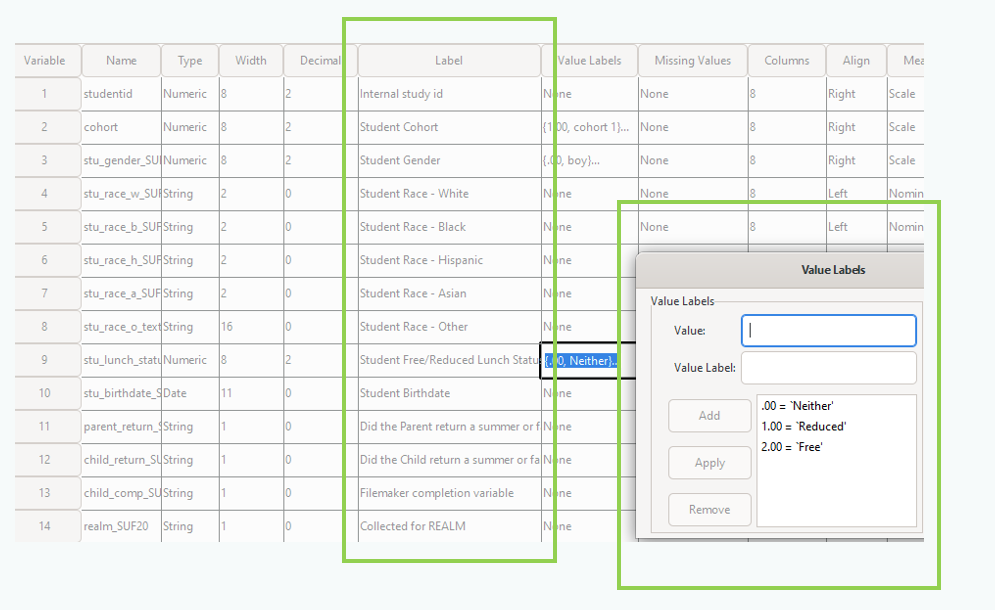
Exercise
What data quality issues do you detect for the interpretable indicator?
01:00
Solution
- Spaces and special characters used in variable names
- Some variable names are unclear
- Inconsistent use of capitalization
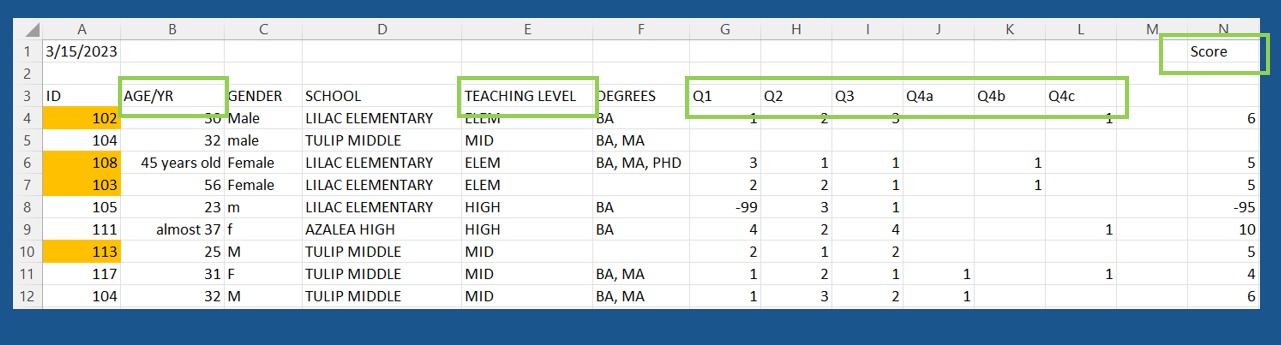
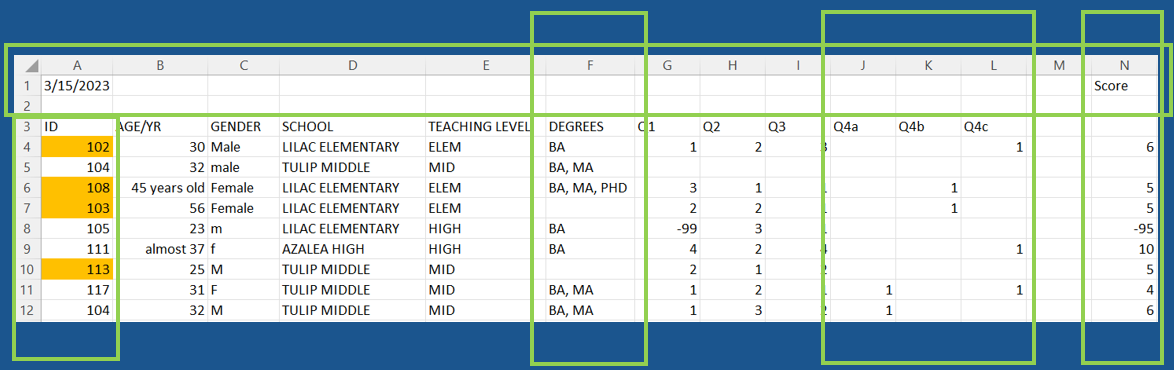
Complete
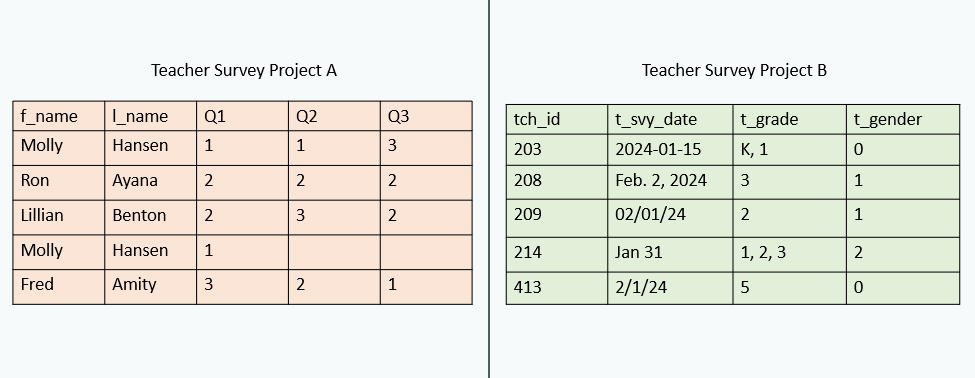
Tracking Database

Data Dictionary
Exercise
What data quality issues do you detect for the complete indicator?
01:00
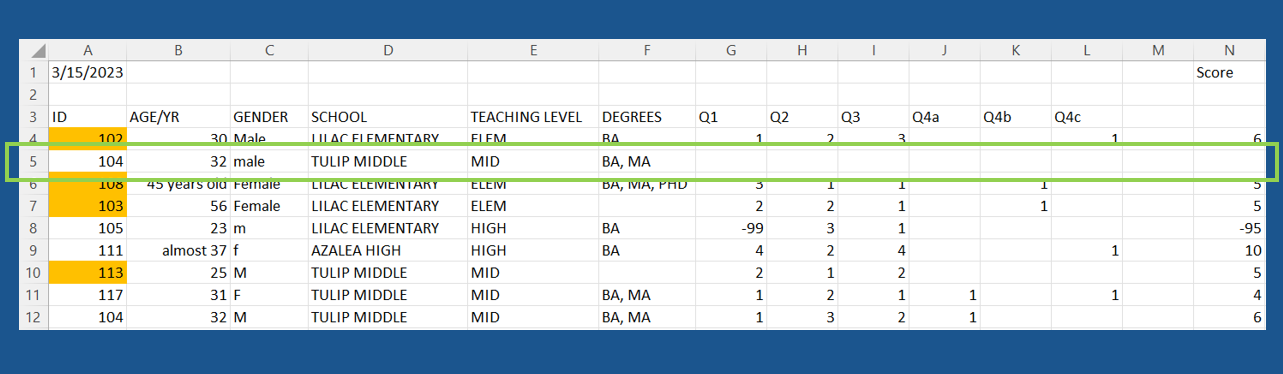
Solution
- The data contain a duplicate ID (104)
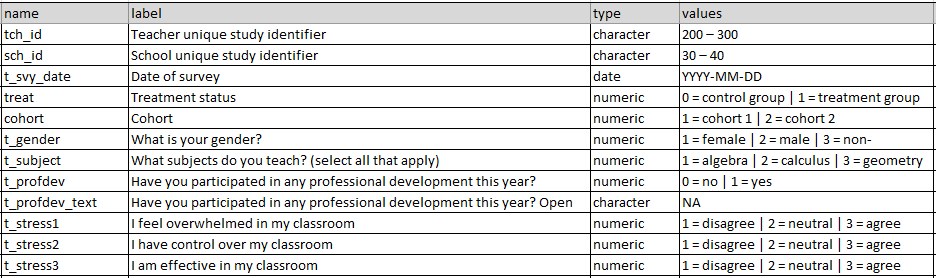
Valid
- Variables conform to the planned constraints
- Planned variable types (e.g.,
numeric,character,date) - Allowable variable values and ranges (e.g.,
1-5) - Item-level missingness aligns with variable universe rules and skip patterns
- Planned variable types (e.g.,
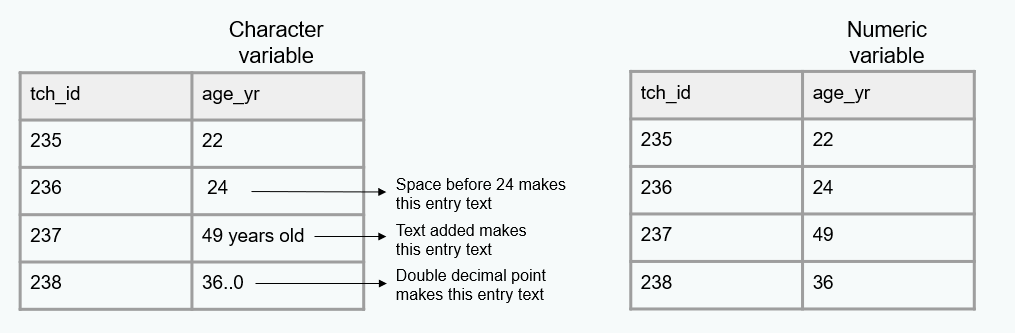
Valid
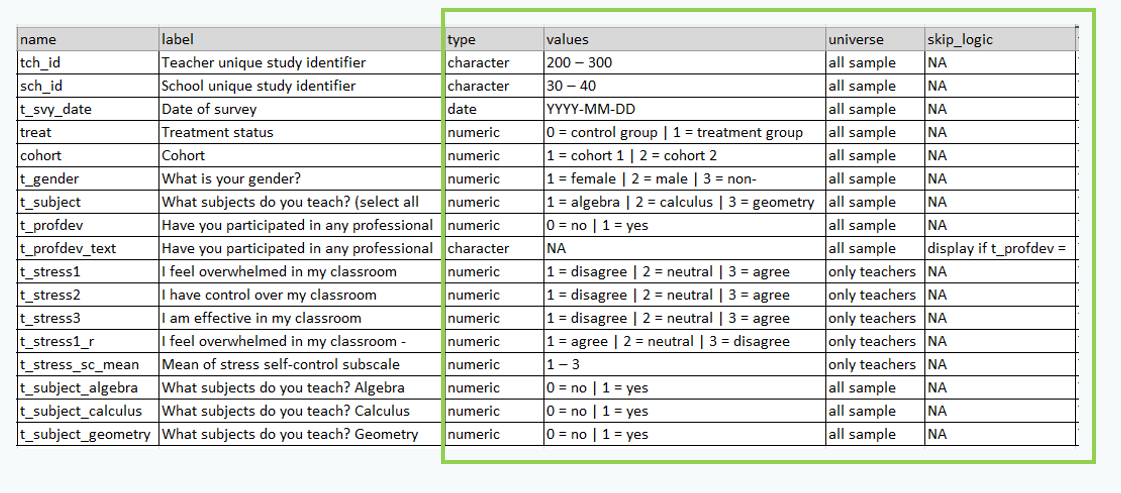
Exercise
What data quality issues do you detect for the valid indicator?
01:00
Solution
AGE/YRdoes not adhere to our planned variable type- Values in
Scorefall out of our expected range
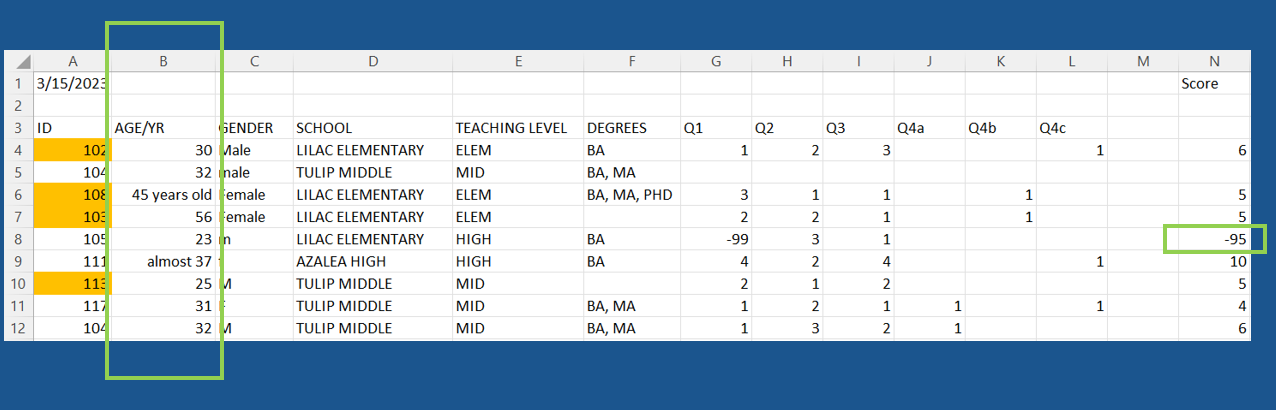
Exercise
What data quality issues do you detect for the accurate indicator?
01:00
Solution
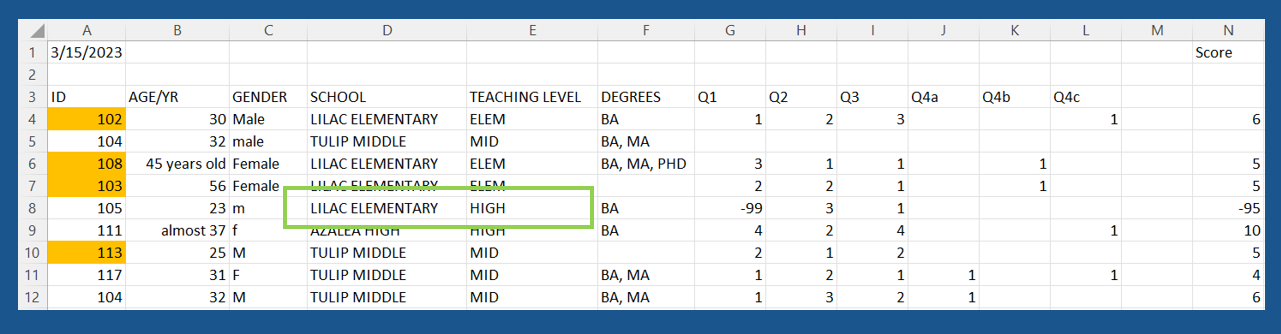
- ID 105 has conflicting information for
TEACHING LEVELandSCHOOL
Consistent
Variable values are consistently measured, formatted, or categorized within a column
Variables are consistently measured across collections of the same form
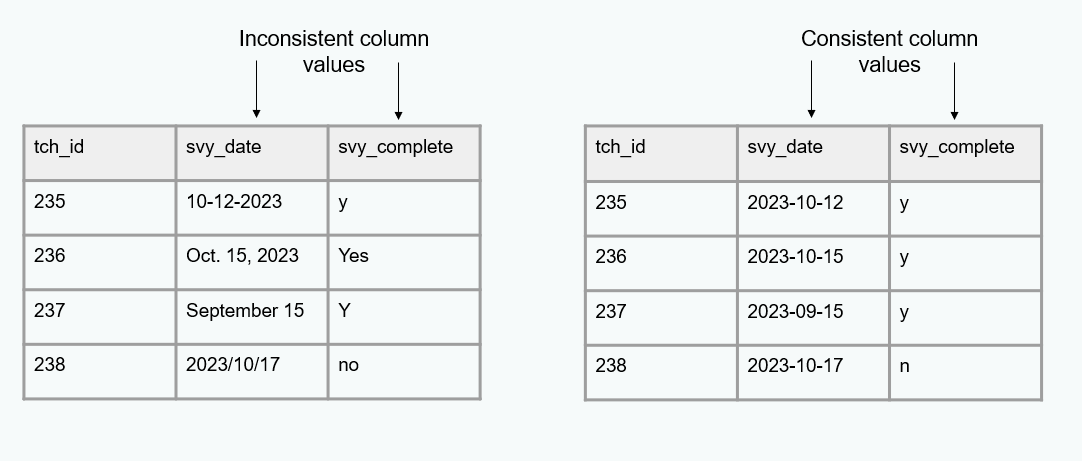
Exercise
What data quality issues do you detect for the consistent indicator?
01:00
Solution
- Values for
GENDERare not consistently categorized
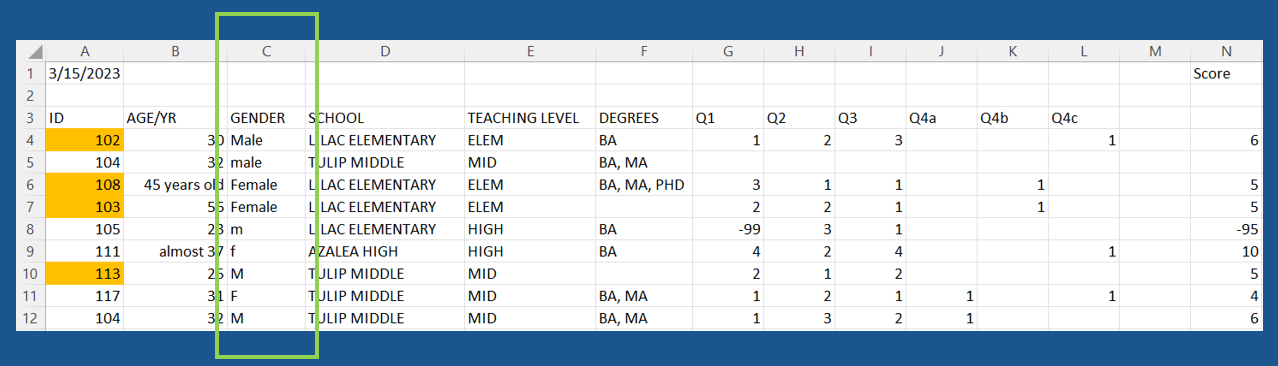
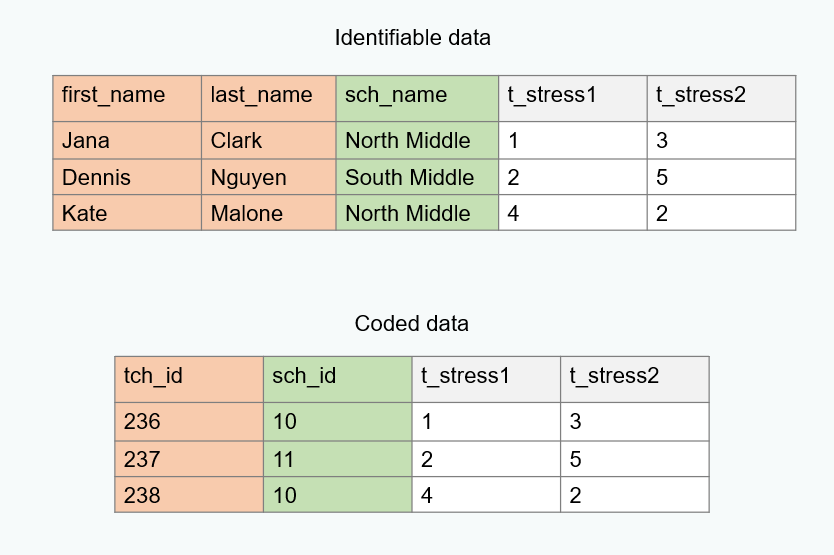
De-identified
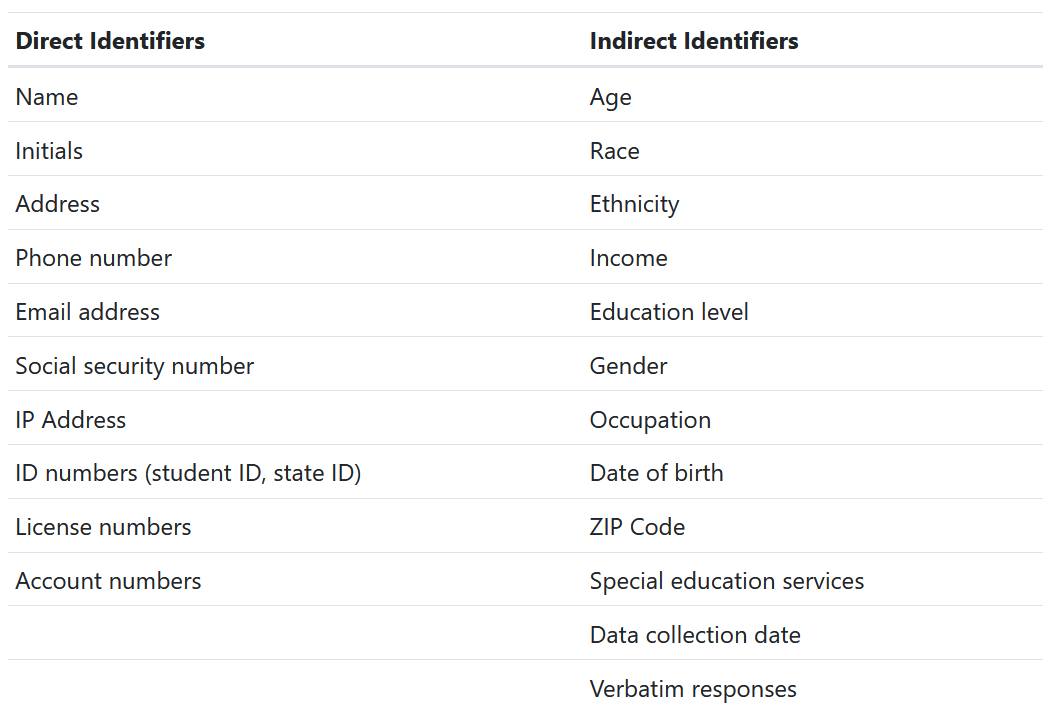
De-identified
- Direct identifiers are removed
Exercise
What data quality issues do you detect for the de-identified indicator?
01:00
Solution
- Replace School Name with an unique ID
- Review outliers and combination of demographics to see if other alterations are necessary
Data Cleaning
Import raw data
Review data
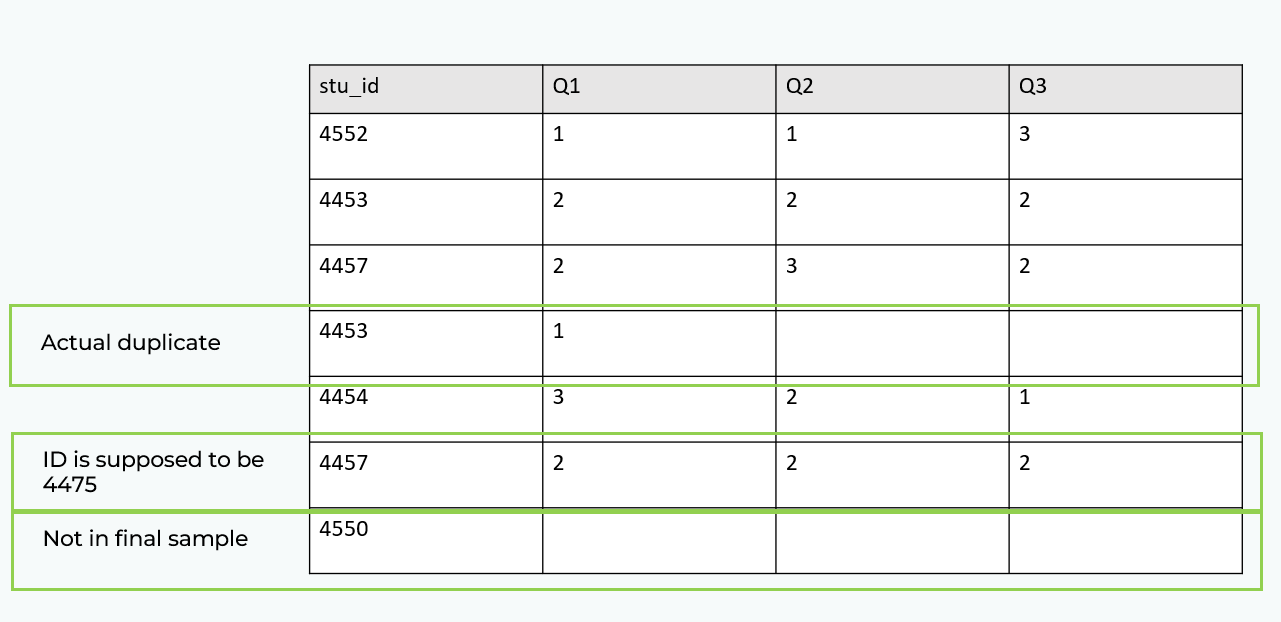
Find missing data
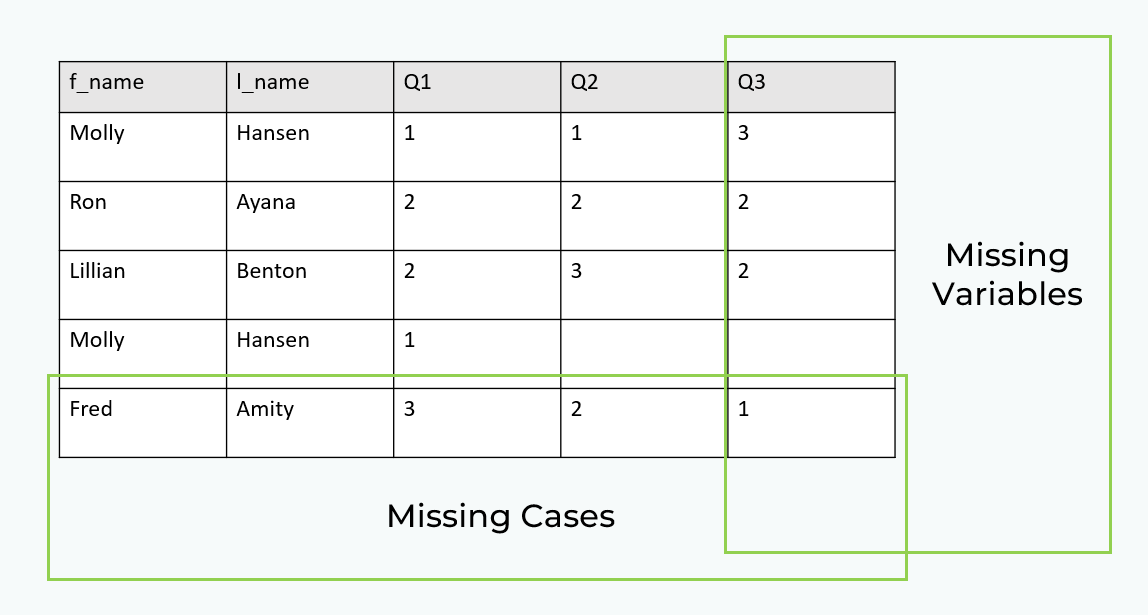
Adjust the sample
De-identify data
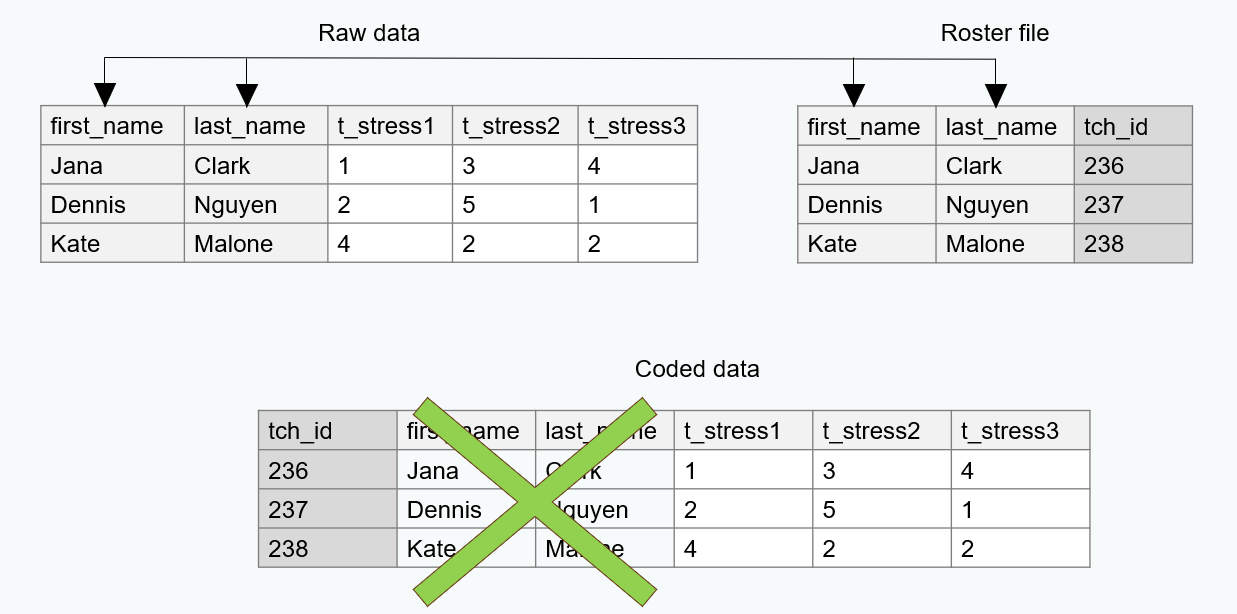
De-identify data
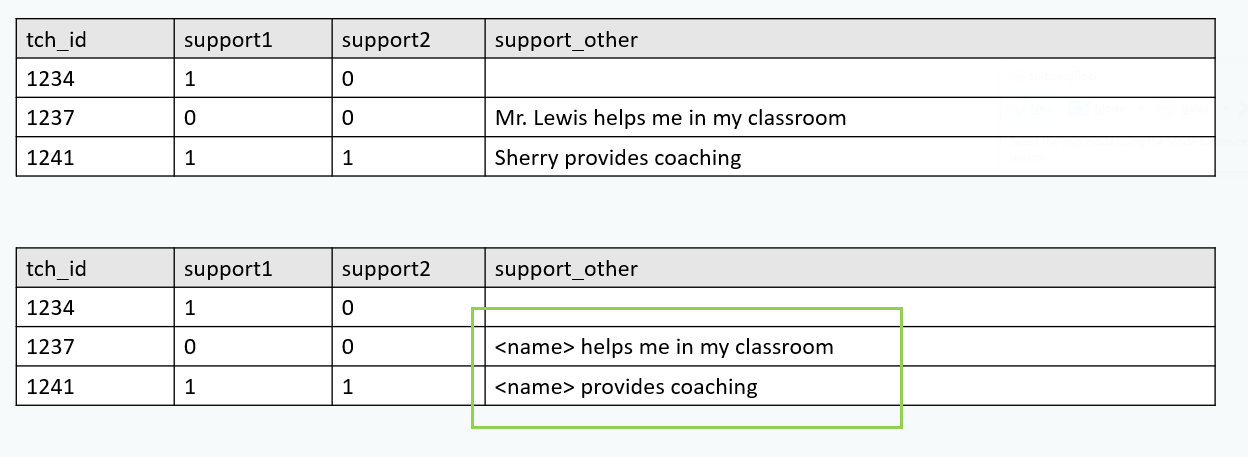
De-identify data
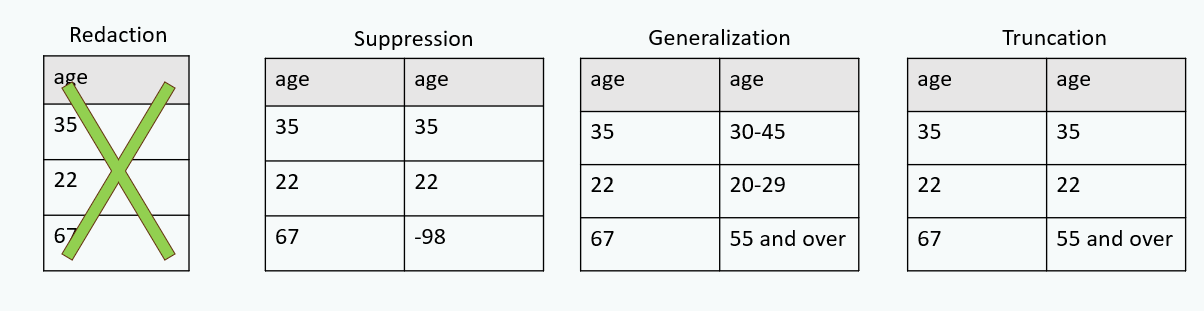
| Source | Resource |
|---|---|
| Alena Filip | Table 2 provides pros and cons of various de-identification methods |
| J-PAL | Table 3 provides a list of direct and indirect identifiers and recommended removal methods |
| Schatschneider, et.al | Deidentifying Data Guide |
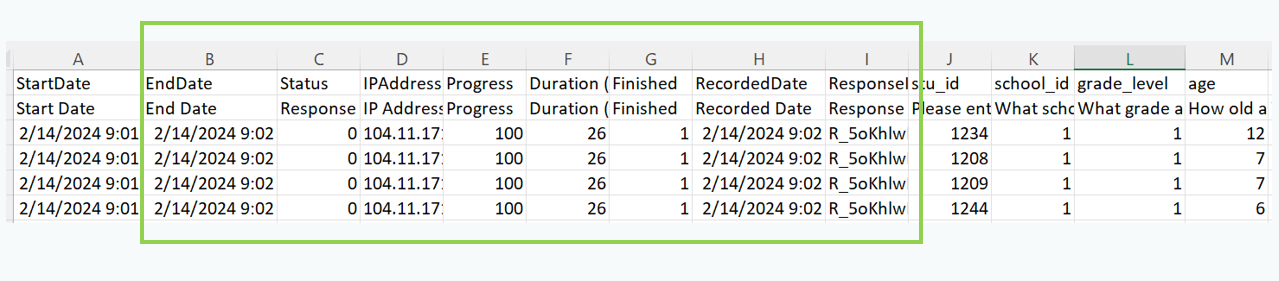
Drop irrelevant columns
Split columns
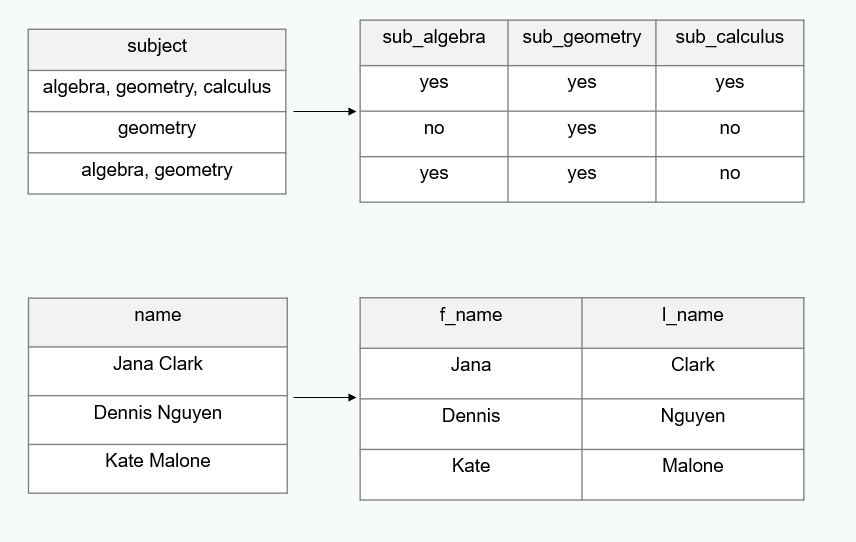
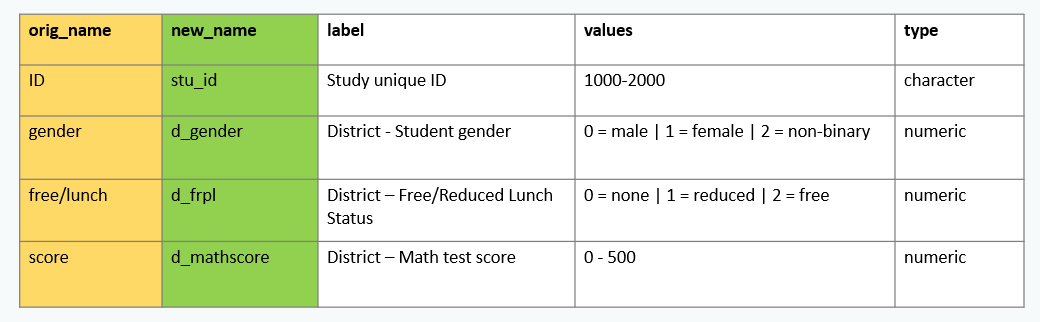
Rename variables
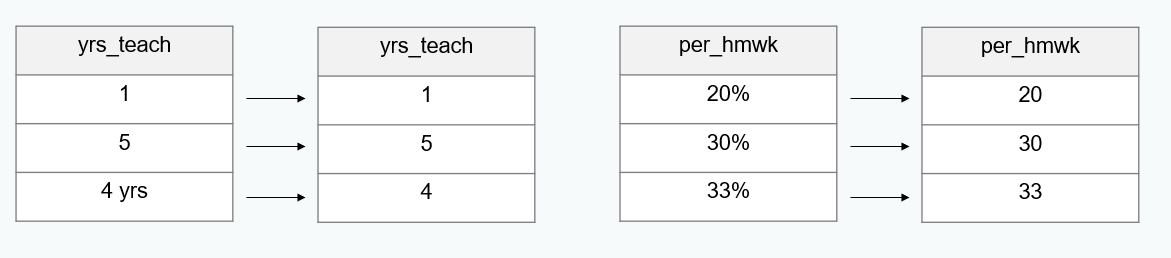
Normalize variables
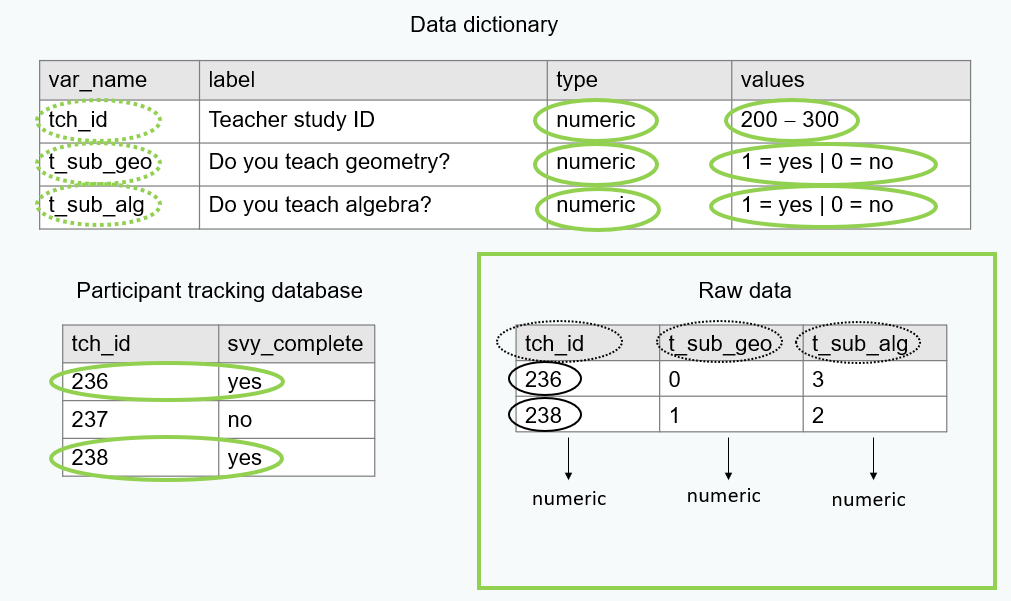
- Compare the variable types in your raw data to the types you expected in your data dictionary.
- Do they align? If not, what needs to be done so that they do
Standardize variables
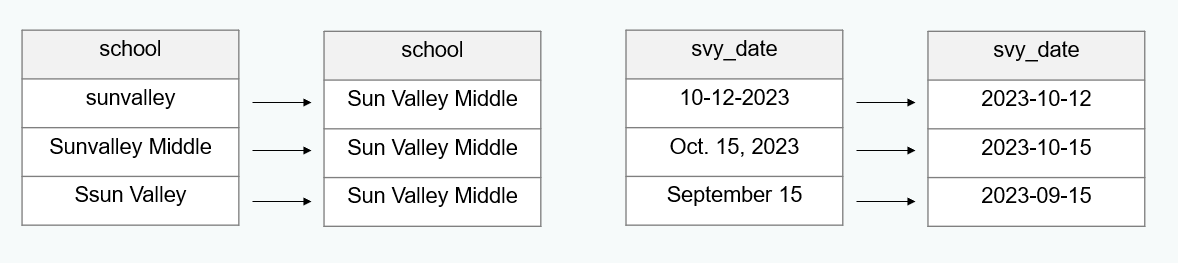
- Are columns consistently measured, categorized, and formatted according to your data dictionary?
- If not, what needs to be done so that they are
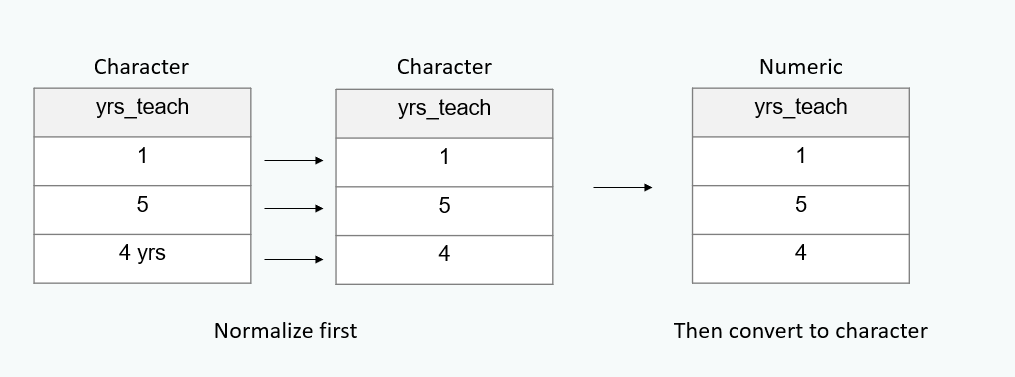
Update variable types
Recode variables
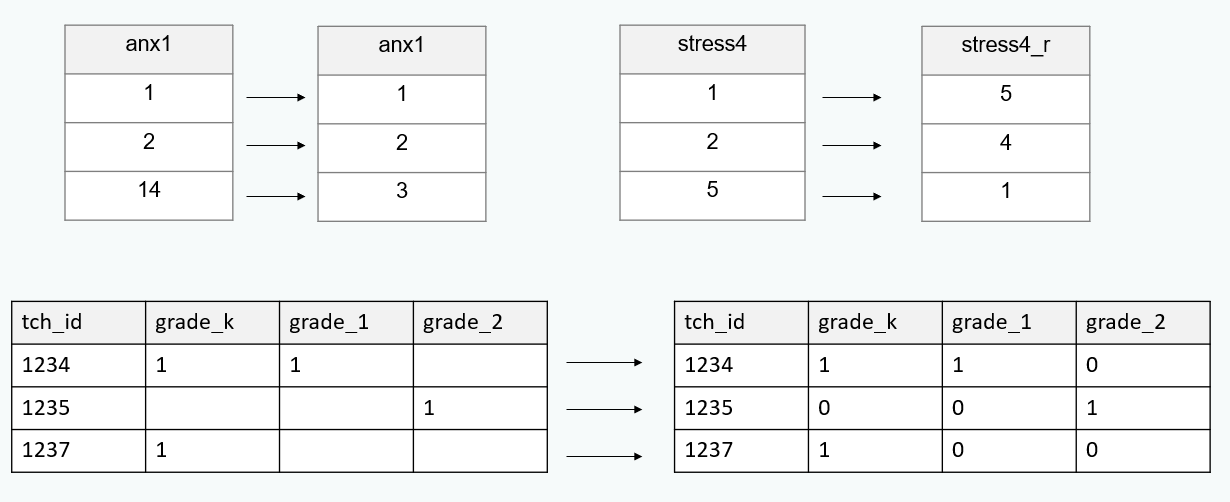
Construct additional variables

Add missing values
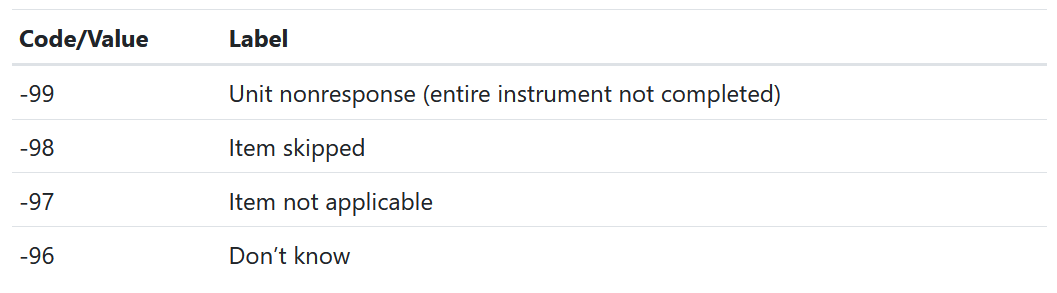
Data validation


Data validation
- Documentation errors
- Fix in documentation
- Data cleaning errors
- Fix in your cleaning process
- Data entry/export process errors
- Fix at the source and export new raw file
- True values that are inaccurate, uninterpretable, or outside of a valid range
- Leave the data as is (document the issue)
- Recode those values to designated error code
- Create data quality indicators
- Choose one source of truth for inconsistent values
- Use logical/deductive editing
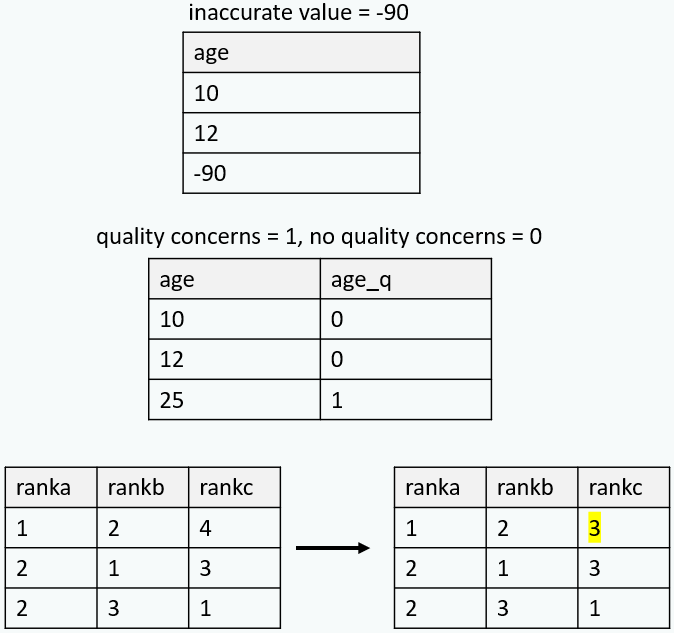
Export data
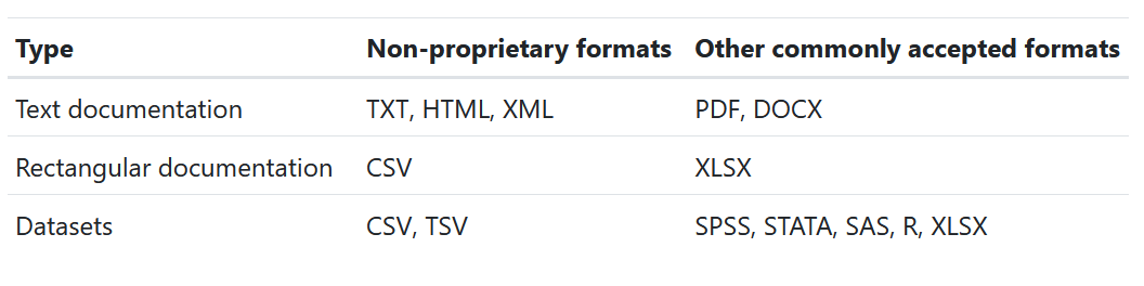
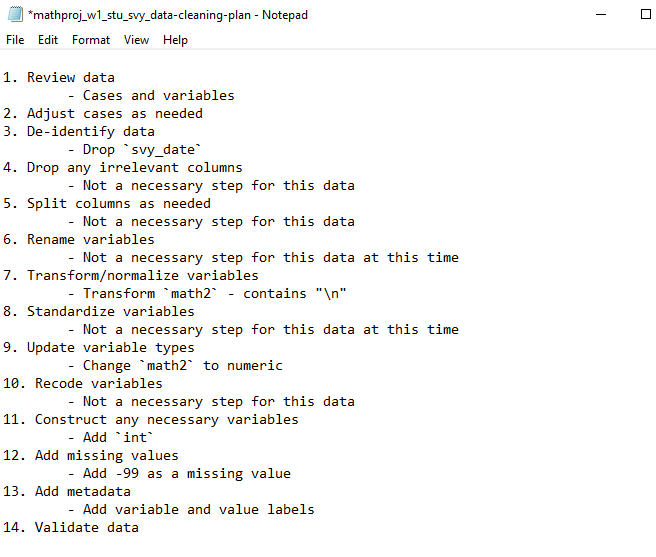
Creating a data cleaning plan
BREAK!

RStudio Pane Layout
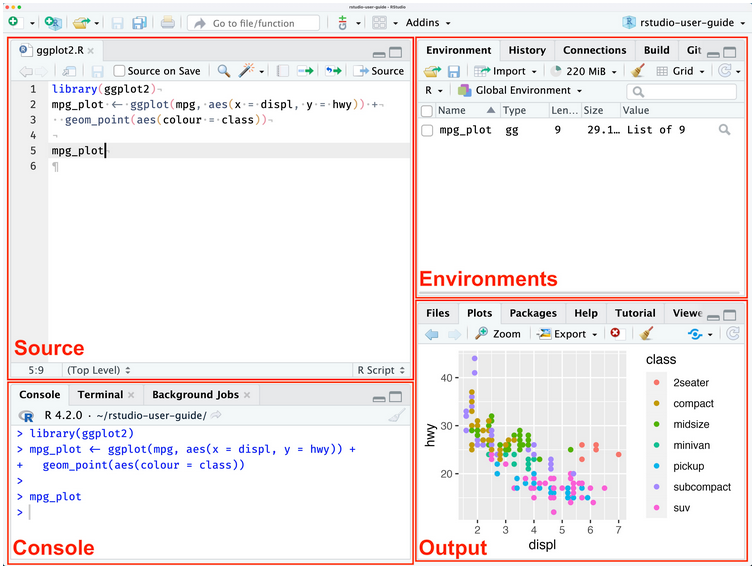
Image from RStudio User Guide
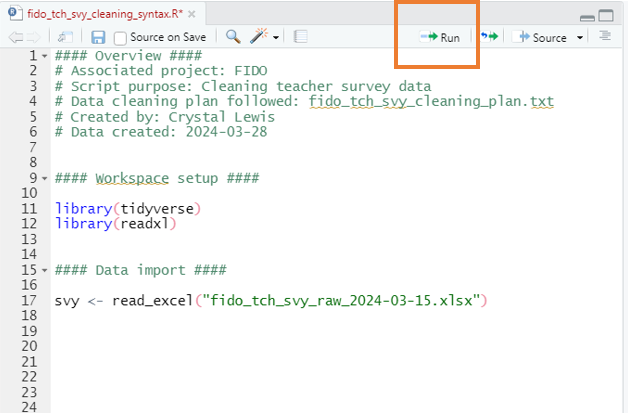
Script Files
R Script File
R Markdown File
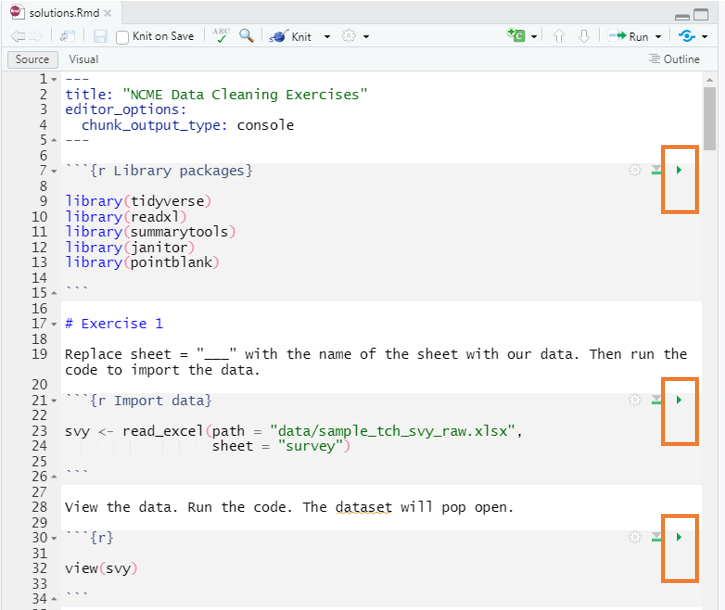
Scenario
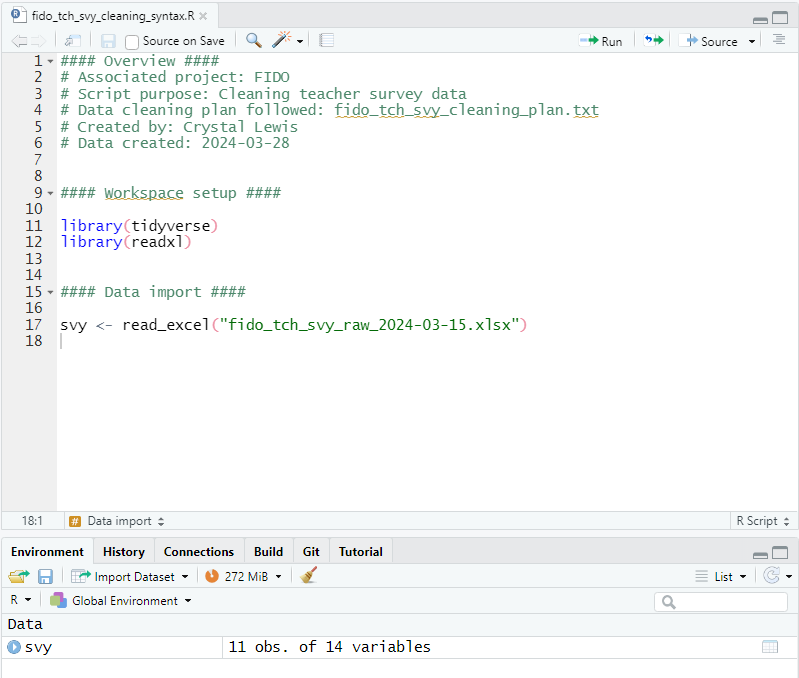
- A team member has just collected a teacher survey and has exported a raw data file.
- They have asked you to clean the file up for the purposes of data sharing.
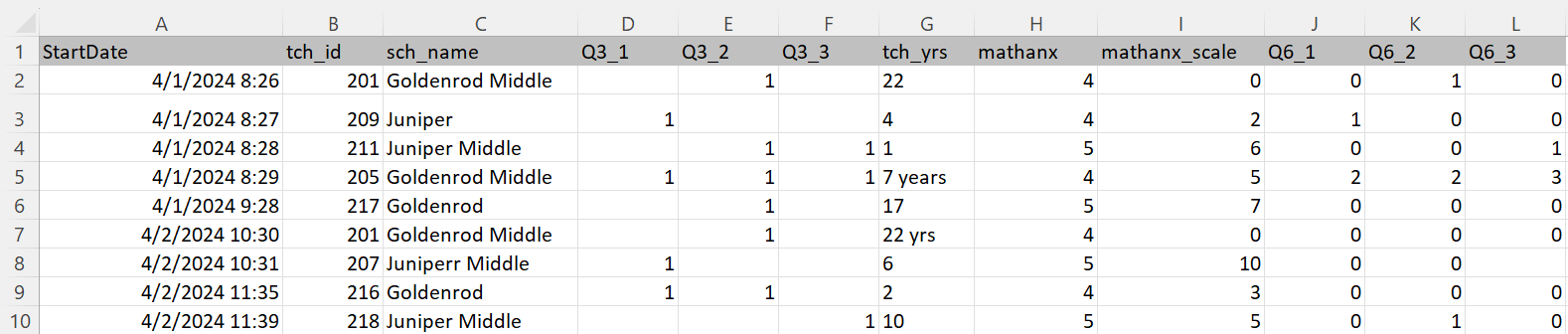
Import our file
read_excel()has several arguments.- path
- Name of the file, plus folder names as needed
- “data/w1_stu_obs_raw.xlsx”
- sheet = NULL
- col_names = TRUE
- na = “”
- skip = 0
- path
- Type
?read_excel()in your console to see more arguments
Review our data
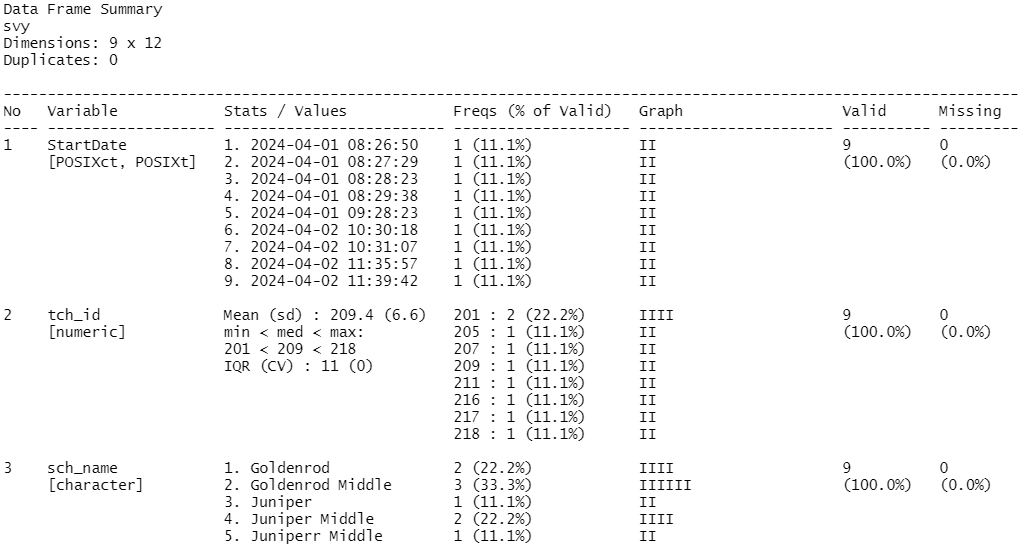
Validate data
- Create tables of information
dplyr::count(),janitor::tabyl()
- Create graphs
ggplot2
- Calculate summary statistics
- All of the functions from “Review the data” section
- Create codebooks
codebookr,memisc,sjPlot
- Create tests that pass/fail based on a set of criteria
pointblank,validate,assertr,dataquieR
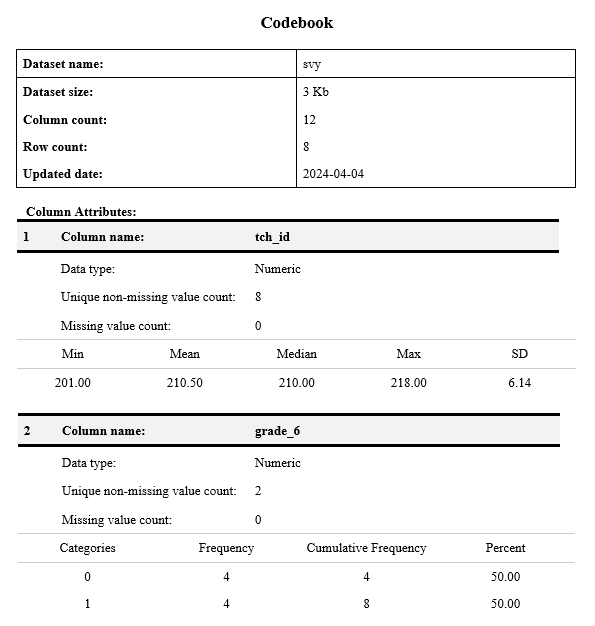
Validate data
Here we are using the pointblank package to develop some validation tests
create_agent(df) |>
rows_distinct(columns = vars(stu_id)) |>
col_vals_not_null(columns = vars(stu_id)) |>
col_vals_between(columns = vars(stu_id), left = 300, right = 500, na_pass = FALSE) |>
col_is_numeric(columns = vars(age, test_score)) |>
col_vals_between(columns = vars(test_score), left = 0, right = 500, na_pass = TRUE) |>
interrogate()![]()
Coding best practices
- Use a coding template
- Follow a coding style guide
- Use relative file paths
- ❌ “C:/Users/Crystal/Desktop/project/data/raw_file.csv”
- ✔️ “data/raw_file.csv”
- Write all cleaning steps in code
- Comment every step in your code
- Check all of your work throughout
- If possible, have someone else review your code
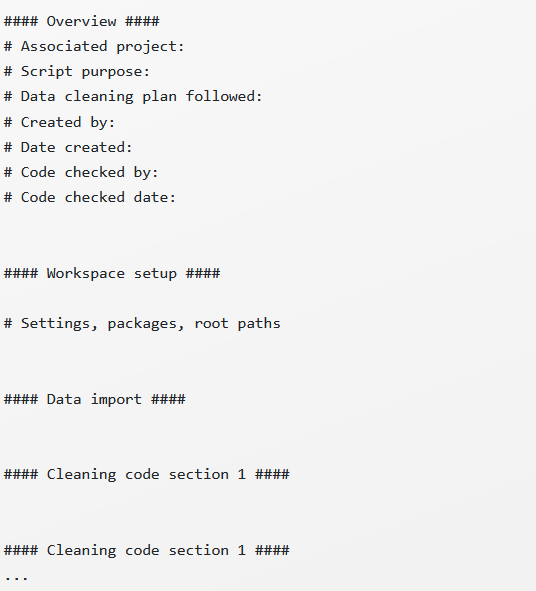
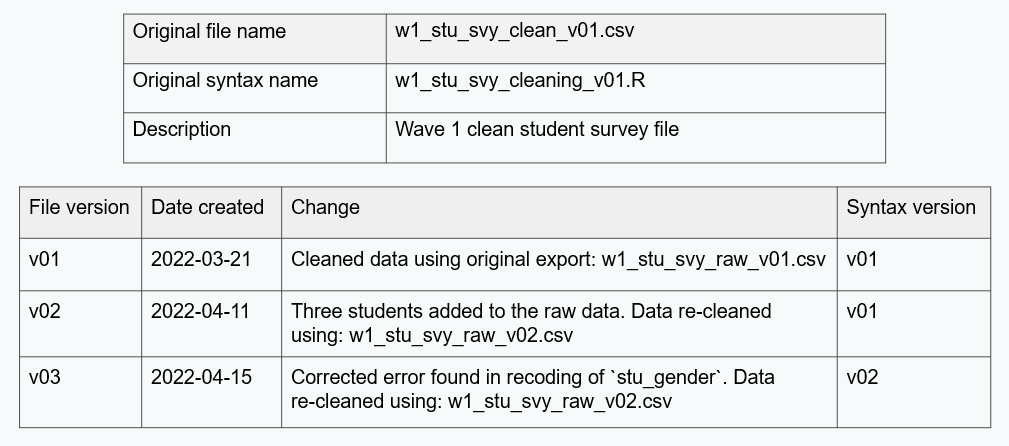
Versioning
- Version your code (“sample_tch_svy_cleaning_v01.R”)
- Version your files (“sample_tch_svy_clean_v01.csv”)
- Make notes in a changelog.
Project-level documentation
- Funding source
- Overview of study
- Setting and sample
- Project timeline
- Measures used
- Overview of study procedures
- Recruitment, consent, data collection
- Data preparation and processing
- Data quality monitoring, de-identification procedures, decision rules
- Appendices
- Copies of instruments, consort diagrams

Data-level documentation
README

Data Cleaning Plan

Variable-level documentation
Data dictionary

Codebook
Repository Metadata
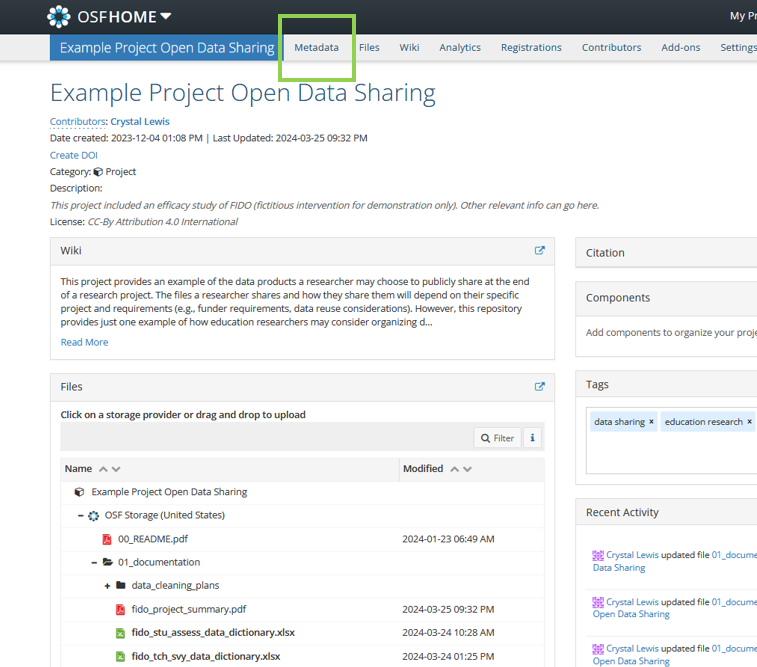
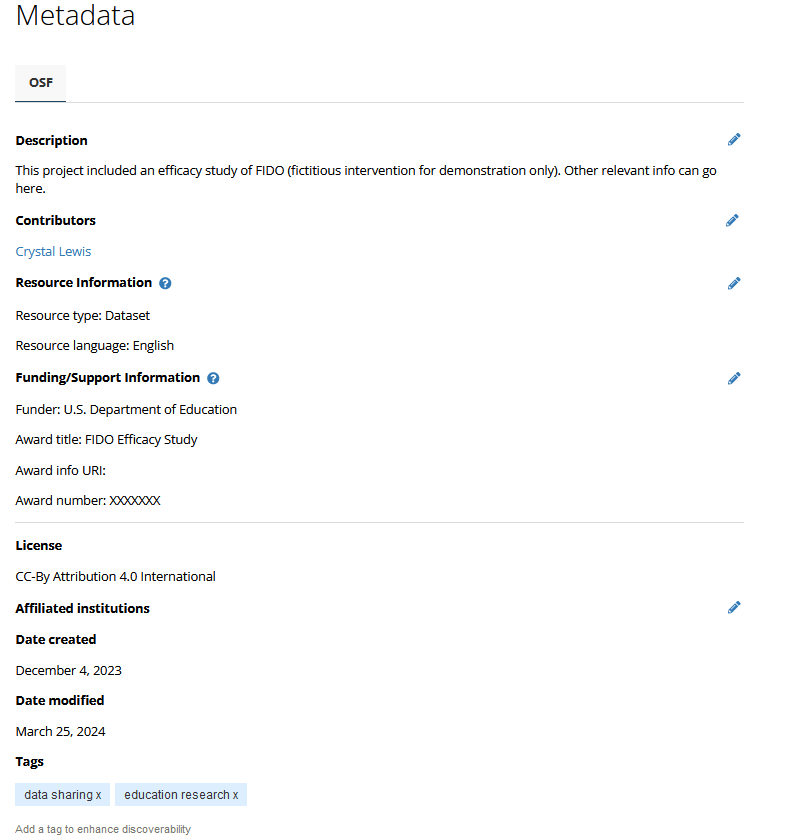
Thank you!
🌟 Please provide feedback on this workshop using this short survey.
https://forms.gle/qVTvVgP8nafbAuXT8
🌟 Stay connected!
https://cghlewis.com/
https://www.linkedin.com/in/crystal-lewis-922b4193/
https://github.com/Cghlewis
