Style Guide
You can view slides from this talk here
Overview
A style guide is such an integral piece to data management, I am giving it its own section! We will cover best practices for file structures, file naming and versioning, variable naming, and value coding. Whatever rules you put in place, make sure they are written down, stored somewhere that is accessible to the entire team (for example a team wiki or a README) and that all staff are trained to follow the style guide protocols. I highly recommend applying this style guide across all projects and therefore putting this style guide in a team folder. If there is any style that is specific to a certain project, you will want to place that style guide at the top of a project folder in a README or on a project wiki.
Reasons a style guide is imperative include:
- Standardization (within and across projects)
- Interpretation: Consistent and clear structure, naming, and coding allows your files and variables to be findable and understandable to humans and computers.
- Reproducibility: If the organization of your file paths, file naming, or variable naming constantly changes, that undermines the reproducibility of any data management or analysis code you have written.
Directory Structure
As I mentioned in training 2, how you set up your directory structure is based on your preferences. However, it is important to get that structure written out in a style guide so that everyone is following the same rules within and across projects.
Useful guidelines for setting up directory structure include:
- Strike a balance between a deep and shallow structure
- Too shallow leads to too many files in one folder, difficult to sort through
- Too deep leads to too many clicks to get to one file, plus file paths can max out with too many characters (ex: SharePoint has a path limit of 260 characters)
- Create folders that are specific enough that you can limit access (ex: participant database folder that only houses your participant database and you limit access to it)
- Make your folder names meaningful and easy to understand
- Make your folder names machine readable
- Don’t use spaces or punctuation in your folder names
- Consider using
_or-to separate words within the same piece of metadata
- Be consistent with capitalization (ex: use all lower case for example)
- Decide if you want an archive folder to move old files into or do you want to leave previous versions in the same folder
An example style guide for your directory structure might look like this:
- All project directories follow this hierarchical metadata structure
- Level 1: Name of project
- Level 2: Life cycle folders
- Level 3: Time period/Data collection wave folders (if
relevant)
- Level 4: Participant folder (if relevent)
- Level 5: Specific content folder
- Level 6: Archive folders
- Level 1: Name of project
- All folders should be named according to these rules
- Meaningful name but no longer than 20 characters
- No spaces or periods in folder names
- Only use lower case letters
- Use
-to separate words
- Meaningful name but no longer than 20 characters
- All previous versions of files must be placed into their respective
archive folder
- README_versioning.txt placed in each folder to document changes between versions
Here is an example of a directory structure that would be created based on that style guide:
levelName
1 project-new
2 ¦--README_style-guide.txt
3 ¦--intervention
4 ¦ °--cohort-1
5 ¦ °--coaching_materials
6 ¦ ¦--README_versioning.txt
7 ¦ °--archive
8 ¦--project-mgmt
9 ¦ °--cohort-1
10 ¦ °--scheduling-materials
11 ¦ ¦--README_versioning.txt
12 ¦ °--archive
13 ¦--documentation
14 ¦ ¦--protocols
15 ¦ ¦ ¦--README_versioning.txt
16 ¦ ¦ °--archive
17 ¦ ¦--data-dictionary
18 ¦ ¦ ¦--README_versioning.txt
19 ¦ ¦ °--archive
20 ¦ ¦--codebook
21 ¦ ¦ ¦--README_versioning.txt
22 ¦ ¦ °--archive
23 ¦ °--cohort-1
24 ¦ ¦--student_measures
25 ¦ ¦ ¦--README_versioning.txt
26 ¦ ¦ °--archive
27 ¦ °--teacher_measures
28 ¦ ¦--README_versioning.txt
29 ¦ °--archive
30 ¦--data
31 ¦ °--cohort-1
32 ¦ °--student
33 ¦ ¦--raw
34 ¦ ¦ ¦--README_versioning.txt
35 ¦ ¦ °--archive
36 ¦ ¦--syntax
37 ¦ ¦ ¦--README_versioning.txt
38 ¦ ¦ °--archive
39 ¦ °--clean
40 ¦ ¦--README_versioning.txt
41 ¦ °--archive
42 °--tracking
43 °--cohort-1
44 ¦--participant-database
45 ¦ ¦--README_versioning.txt
46 ¦ °--archive
47 °--parent_consents Quick thought: Versioning Documents
Some sort of versioning is absolutely necessary to track changes in your documents throughout the life cycle of your project. If you use a platform that has versioning (ex: Git, SharePoint, Box), which I highly recommend, then you do not need to add the versioning README files to your folders or create archive folders. Through versioning software, you can save over previous versions of files, without having to add an extension such as v01, v02. And when you save over previous versions, the platform tracks the date, allows you to comment on the changes made from your previous version, and at any time, you can view previous versions of the document, review comments from those versions and even retrieve previous versions. If, however, your team does not use versioning software, adding extensions to file names and READMEs to file folders is a viable alternative.
A few important pieces of information before moving on:
- In your data folder, always include a raw data folder. You always want to keep untouched, raw versions of every data file that you collect, receive, or download. You never know if or when you may need to go back to that raw data after you cleaned and manipulated it for analysis.
- Always limit access to any project folder that holds Personally Identifiable Information (PII) (such as your tracking folder) as well as your data folder for security purposes.
- One other thing you can do to protect files that you don’t want
others to accidentally edit, is write-protect them (Karl Broman. To
do this on a PC:
- Right-click on the file
- Select “Properties”
- In the “General” tab, at the bottom is a section called
“Attributes”
- Select the box “Read Only”
- Right-click on the file
- Last, another school of thought is that you shouldn’t use folders at all. For example, SharePoint advocates for the use metadata/tagging to organize and find files rather than using folders. I do not have experience with this so I won’t elaborate further. But here are resources on tagging in SharePoint and Windows 10 if you would like more information.
Resources:
📑 Sofware
Carpentry
📑 CESSDA
📑 Helsinki
University Library
📑 Teague
Henry
📑 BIDS
📑 Stanford
Medical
📑 Danielle
Navarro
📑 Project TIER
(Teaching Integrity in Empirical Research) provides a protocol as
well as a template for organizing your files for data processing and
analysis
File Naming
If you are like me, or most of humanity, you are guilty of naming
files something like research report final.docx and
research report final-2.docx and
research report-2-dan edits.docx. It happens, but as you
can see this can makes it very confusing to know any details about what
these documents are? What is this research report on? What is the actual
final version? When were the edits made on these documents? What are the
differences between these documents?
This is why adding file naming to your style guide is so important. It sets the protocol for you and your entire team to use standardized, descriptive, organized, and ultimately human and machine-readable file names to remove any future confusion.
General file naming conventions to follow include:
- Never use spaces between words. They can often break a URL when shared.
- Never use special characters. They can have meaning within programming languages and can cause problems.
- Use
_between metadata (different chunks) and-within metadata (different words that are part of the same chunk). This not only helps to make the name human readable but also allows your computer to read and search files easier.- It is worth noting that
_can be difficult to read when file names are included in links that are underlined to denote that the path is clickable (for example when sharing a SharePoint link to a document). So it is worth considering this when choosing to use underscores in file names.
- It is worth noting that
- Choose to either only use lower case letters, or be specific where to use capital letters (ex: at the start of every new word)
- Make names descriptive (a user should be able to understand the contents of the file without opening it)
- Consider limiting the number of characters to prevent hitting your path limit
- Keep redundant metadata in file name
- Ex: always put time period in file name, even if the file is currently housed in a time period folder
- Ex: always put the project name in the file name, even if the file is currently housed in a project folder
- This reduces confusion if you ever move a file to a different folder
- It also makes your files searchable
- Pick an order for file name metadata and stick to it. Ex:
- Order of use (if relevant–and always add a 0 before single digits)
- Project
- Cohort/Data collection wave (if relevant)
- Participant
- Measure
- Further description
- Version or Date
- Do not use
\in dates. Format dates in one of two ways (pick one and add it to the style guide):- YYYY-MM-DD
- YYYYMMDD (this way reduces the number of characters in your file name but may be more difficult to read)
- These dates will be sortable
- When adding versions, pick a format and add it to your style guide.
Consider left padding with 0 before single digit numbers to keep the
file name the same length as it grows. Ex:
- v01
- v02
- If your files need to be run in a sequential order, add the order number to the beginning of the file name, with leading zeros to ensure proper sorting
- Choose abbreviations to use for common names/phrases and add them to your style guide
Example file naming style guide:
- Never use spaces between words.
- Never use special characters.
- Use
_between metadata and-to separate words within metadata - Use the following metadata file naming order:
- Order of use (if relevant–and always add a 0 before single digits)
- Project
- Cohort/Wave (if relevant)
- Participant
- Measure
- Further description
- Date (always add)
- Version (if necessary)
- Format dates as YYYY-MM-DD
- If there are multiple versions of a document on the same date, version using v# with a leading 0.
- Only use lower case letters
- Keep names under 45 characters (FYI: this is excessive, many people will recommend shorter names)
- Use the following abbreviations
- student = stu
- teacher = tch
- survey = svy
- cohort = c
- Project Discipline in Secondary Classrooms = dsc
- Examples of this format:
01_dsc_c1_stu_svy_cleaning-syntax_2021-01-22.R01_dsc_c1_stu_svy_cleaning-syntax_2021-01-22v02.Rdsc_stu_svy_protocol_2020-10-01.docxdsc_c1_tch_svy_raw-download_2020-08-03.csv
Resources:
📑 Stanford
Libraries
📑 Washington
University in St. Louis Libraries
📑 Caltech
Library
📑 Jenny
Bryan
📑 Teague
Henry
📑 Danielle
Navarro
Variable Naming
Variable naming protocol should be created early in the project and added to your style guide. You will need this protocol in place to start creating your data dictionary.
There are many best practices and considerations around variable naming.
- Names should be meaningful
- Instead of q1 use gender
- If a variable is a part of a scale, consider using an abbreviation
of that scale plus the scale item number (add the number last to make
data manipulations easier)
- toca1
- Don’t name a variable any keywords (such as
if,for,repeat) or functions used in any programming language - Set a character limit
- Most statistical programs have a limit on variable name characters
- SPSS is 64
- Stata is 32
- SAS is 32
- Mplus is 8!
- R is 10,000 🙀
- Most statistical programs have a limit on variable name characters
- If you have used the question/scale before, consider keeping the
variable name the same across projects
- The hosts of the Within and Between podcast even suggest the idea of standardizing variable names across the field for commonly used assessments (such as the Woodcock Johnson). Hear more on Data Management Episode 1.
- Use the same variable name across time in a project
- If you asked “What is your anxiety level” in fall 2019 and you named it anxiety1, and you ask “What is your anxiety level” again in spring 2020, name it anxiety1 again.
- Don’t use spaces or special characters (except
_)-is not allowed in programs such as R and SPSS as it can be mistaken for a minus sign- While
.is allowed in R and SPSS it is not allowed in Stata so it’s best to just avoid using it
- Do not start a variable name with a number
- Be consistent with delimiters and capitalization
- Pascal case (ScaleSum)
- Snake case (scale_sum)–preferred method for variable names
- Camel case (scaleSum)
- Kebab case (scale-sum)–don’t use for variable names
- Train case (Scale-Sum)–don’t use for variable names
- All variable names should be unique
- If you collect student gender from a survey and from their school records, consider naming one s_gender and the other d_gender
- Consider denoting reverse coding in the variable name
- scale1_r (to denote that you have reverse coded that question)
- Choose abbreviations to use for common names/phrases
- scaled score = ss
- percentile rank = pr
- Emily Riederer has a great blog post on using controlled vocabularies in variable naming and how that sets up a sort of contract between data producers and data consumers to be able to interpet data usage and lineage.
In addition to best practices, here are other practices that I’ve noticed others implement. You can pick and choose what works best for your team. Just make sure whatever you choose, you put it in your style guide and follow those guidelines all throughout your project.
Some people like to include question ordering in the variable name (personally I’d rather simply keep this information in my data dictionary and not in my actual variable name). Also, this can get complicated if for any reason you add questions to measures and question order changes.
- Ex: q1_gender, q2_race
Some people like to include an indication of the measure in the variable name so you always know what instrument the item came from
- I think this is actually an excellent idea. Ultimately you may
create a student level dataset that includes all data pertaining to a
student, but without referring to documentation, you won’t know which
questions were part of the student self-report and which questions were
part of the teacher rating of a student. You can make this more clear by
adding a prefix to indicate the measure.
- Ex: s = student self-report and t=teacher rating of student
- s_anxiety1 and t_toca1
- I think this is actually an excellent idea. Ultimately you may
create a student level dataset that includes all data pertaining to a
student, but without referring to documentation, you won’t know which
questions were part of the student self-report and which questions were
part of the teacher rating of a student. You can make this more clear by
adding a prefix to indicate the measure.
Last, time is probably the trickiest variable to account for and also the least uniform (in terms of consistency) that I’ve seen across teams/projects. I think people account for time in many different ways and call it many different things. My general note is, whatever you choose, just make sure it is documented very clearly for your team and outsiders to understand. With that said, I am going to give time it’s own section below.
📑 Tara Reynolds and Christopher Schatschnieder have some great recommendations of variable naming as well.
Quick thought: Versioning Variables
We’ve discussed keeping tracks of different versions of documents. But what if the wording or response options for an item/variable substantively change during the project, after you have collected data? Make a rule for variable versioning.
- Example Rule: Add “_v#” on any revised items
- Ex: revised scale1 becomes scale1_v2
Time
If your data is longitudinal, consider time in your variable naming conventions as well.
Depending on how you plan to merge your data, there are two different ways to account for time.
Concatenate time to your variables. You do this if you plan to merge your data across time in wide format. Every participant/case occurs once in your data and all data collected for that participant is in that one row.
Create time variables and add them to your data. You do this if you plan to append your data over time in long format. Every participant/case occurs multiple times in your data, once for each period/wave of data collection.
You do not need to have this decided right at the beginning of your
project. You really don’t even need to decide how to account for time
until you are ready to start merging data across time. Until then, most
likely you will have each dataset stored separately per wave and you
will know when each piece of data is collected by how you name that file
(ex: projecta_w1_stu_survey.csv).
When it comes time to start merging your data (maybe you need the first year of data merged to analyze for a funding report), then you will need to make some decisions about how you want to merge your data. The great thing is, if you choose one method and then decide you need your data in the other format later on, it is very easy to switch back and forth through restructuring your data in a statistical program like R or Stata. We will cover this more in a later training.
Consider a hypothetical, longitudinal randomized controlled trial
You collect data on two cohorts of students and you follow each cohort for two years. Your first cohort of students is recruited in 2018-19 and the second cohort of students is recruited 2020-21. You follow each cohort for 4 waves of data collection. Two waves occur in the fall and spring of the first year, and two waves occur in the fall and spring of the follow-up year.
- If you decide to merge your data in wide format, you will need to concatenate time to your variable names in order to differentiate between the four phq1 and phq2 variables that occur in your data for each wave it was collected. What this exactly looks like is all dependent on your longitudinal study design and your preferences. One example of how you might do this for the hypothetical study is to concatenate time (as well as a form abbreviation) as a prefix to each variable. In addition, have a cohort variable in your data. With those two pieces of information I would know, by referring to documentation, that s1_ for student 30415, is student-report wave 1 (fall) and that since their cohort is 1, the year is 2018. Similarly for the same student, if I looked at s4_, I would know, again through documentation, that s is for the student-report form and that wave 4 occurred in spring of the follow up year and for cohort 1 that occurred in 2020.
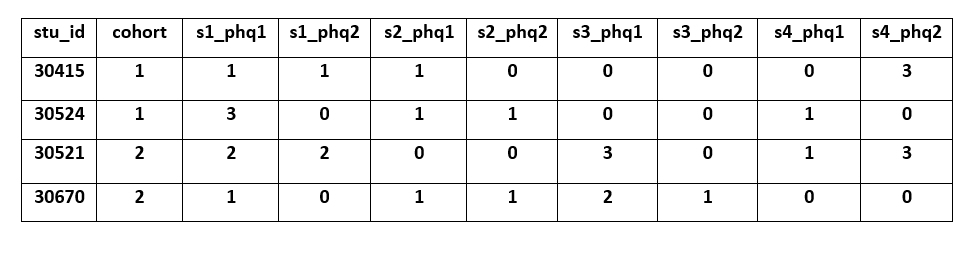
📑 The National Center for Education Statistics has a great example of creating time prefixes for variables in their ECLS-K:2011 documentation on page 7-3.
- If you decide to append data in long format over time then you no longer need to worry about having duplicate variables in a row. However, you will need to create variables in order to capture the aspect of time. Again, what this looks like is all dependent on your longitudinal study design and your preferences. One example of how you might do this for the hypothetical study is to create a wave variable as well as a cohort variable. With those pieces of information I would know that cohort 1, wave 2, for example, occurred in spring 2019.
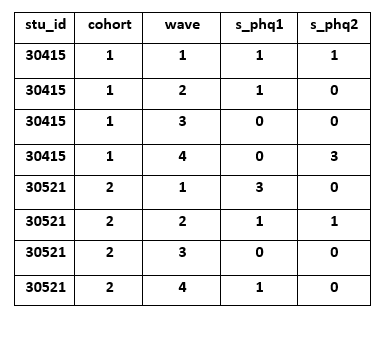
My examples are by no means, the only way to account for time. You really can account for it however it makes sense for your project and team. For example you may use years and seasons (f18,s19,f19,s20) rather than numeric waves (1,2,3,4). As I mentioned early, just make sure to document it thoroughly so that future users know how to interpret time in your data. No matter what though, formatting for time variable names also needs to also go into your style guide. So if you decide to concatenate time to your variable names, in your style guide you will need to make a rule about this (ex: always add time as a prefix, always separate time by an underscore, etc.).
Additional reading on variable naming:
📑 IPA:
Best Practices
📑 Advanced R
📑 Karl
Broman
Quick thought: Add variable naming to documentation
At the end of any project, you will need to add relevant style guide rules to your final documentation (ex: your codebook) so that when you share your data, others know how to interpret your variable names.
Here is an example of how you would explain your variable naming in your documentation if you are merging data in wide format:
All variable names are made up of the following 4
components:
1. measure (s=student survey, t=teacher survey, o=teacher
observation)
2. data collection wave (1=fall, 2=winter, 3=spring)
3. variable/scale name
4. variable/scale #
Sample: s2_toca4 = student survey-winter-toca scale-item4
Value Coding
Similar to variable naming, variable value protocol also needs to be documented early on and standardized within and across projects. Here are some conventions to follow:
- Value codes must be unique
- Do: Assign 1=yes and 0=no
- Don’t: Assign 1=yes and 1=no
- Do: Assign 1=yes and 0=no
- Keep values consistent across the project. Examples:
- Do: Always use 1=yes; 0=no
- Don’t: For some variables use 2=yes; 1=no, for other variables 1=yes; 0=no
- Do: Always use m=male, f=female, n=non-binary
- Don’t: Switch between ‘M’, ‘m’, and ‘male’ to denote male
- Do: Always use 1=yes; 0=no
- Make sure Likert-type scale response option ordering makes sense.
Example:
- Do: Strongly Disagree = 1; Disagree = 2; Agree =3;
Strongly Agree = 4
- Don’t: Strongly Disagree = 1; Disagree = 3; Agree =4; Strongly Agree = 2
- Do: Strongly Disagree = 1; Disagree = 2; Agree =3;
Strongly Agree = 4
- Define missing values
- I am personally okay with leaving missing values as blank, NA, or NULL
- However, you may care about the reason for missing data and need to consider defining missing values based on their properties
- The key is to use extreme values that do not actually occur in your data and to also not use character missing values in a numeric field
Example of missing codes used by NCES:

Additional reading on value coding:
📑 Jessica
Logan, Ph.D.
📑 Data
One
📑 Karl
Broman
Last Thoughts
A style guide can include many other components besides just the four I covered here. For example, in this excellent example of a style guide, created and used by the Harvard Strategic Data Project, they cover folder structure, file naming, and variable naming, as well as rules for commenting code, general coding guidelines and commonly used and accepted abbreviations. You can include anything you want in your style guide that helps you streamline the look, usability, and searchability of your files and data.